Eric J Ma's Website
written by Eric J. Ma on 2017-10-11 | tags: python programming optimization
I profiled PyPy against CPython when running NumPy code, and found it to be very competitive! Read on more to find out why.
A few years on after trying out PyPy for the first time and wrestling with it, I still find it to be pretty awesome.
Now that PyPy officially supports numpy, I'm going to profile a few simple statistical simulation tasks:
- Computing the mean of a number of random number draws.
- Simulating many coin flips
I'll profile each of the tasks four ways:
- Pure Python implementation running from the CPython and PyPy interpreters
numpyimplementation running from the CPython and PyPy interpreters.
So, how do PyPy and CPython fare? Let's show the results up front first.
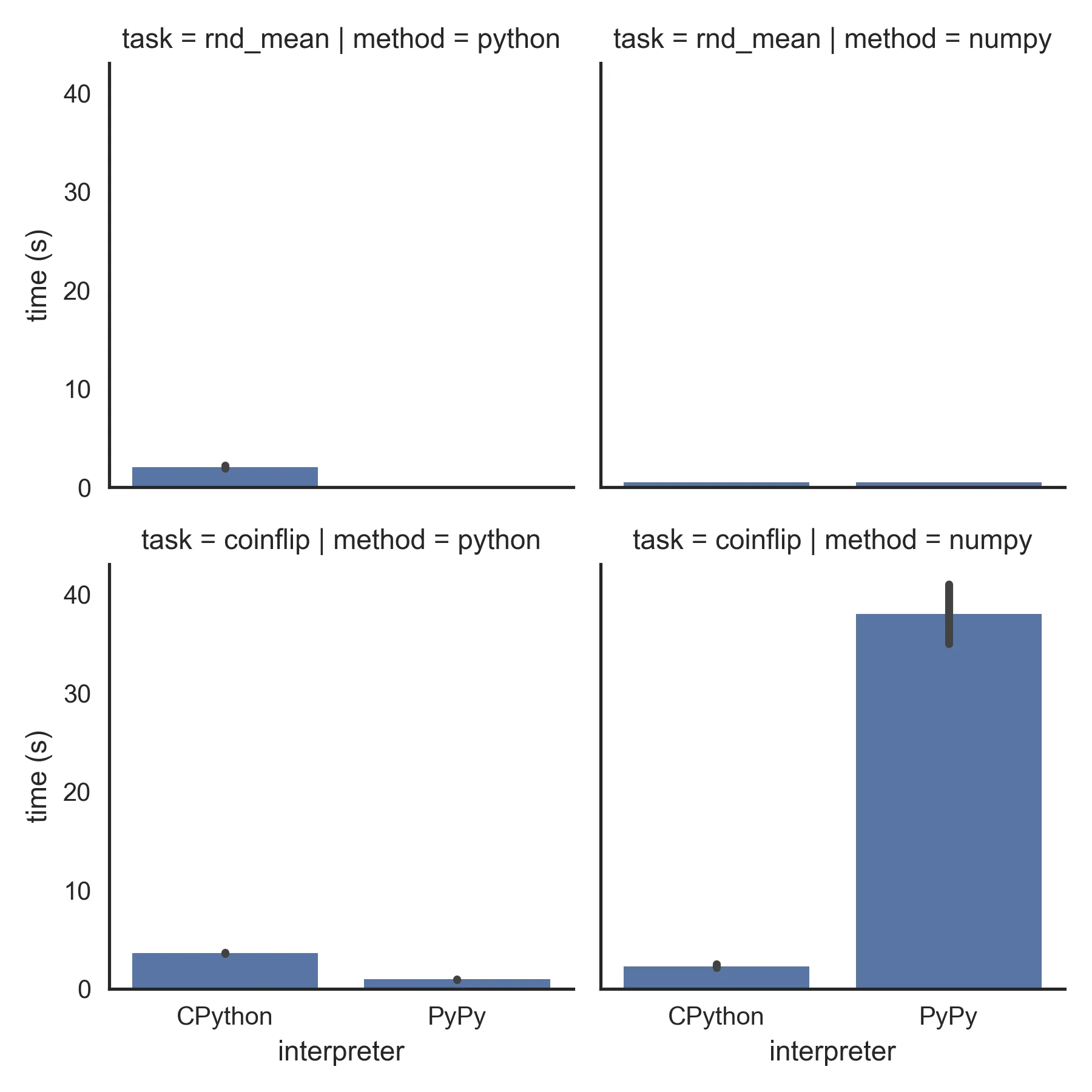
Click on the image to view a higher resolution chart. The raw recorded measurements can be found on Google Sheets.
Here's a description of what's happening:
- (top-left): PyPy is approx. 10X faster than CPython at computing the mean of 10 million random numbers.
- (top-right): When both are running
numpy, the speed is identical. - (bottom-left): When simulating coin flips, PyPy with a custom
binomial()function is about 3X faster than CPython. - (bottom-right): When using
numpyinstead, there is a bottleneck, and PyPy fails badly compared to CPython.
It's pretty clear that when PyPy is dealing with "pure" data (i.e. not having to pass data between Python and C), PyPy runs very, very fast, and, at least in the scenarios tested here, it performs faster than the CPython interpreter. This is consistent with my previous observations, and probably explains why PyPy is very good for code that is very repetitive; the JIT tracer really speeds things up.
That last plot (bottom-right) is a big curiosity. Using the code below, I measured the random number generation is actually just as fast as it should be using CPython, but that PyPy failed badly when I was passing in a numpy array to the Counter() object (from the standard library). I'm not sure what is happening behind-the-scenes, but I have reached out to the PyPy developers to ask what's going on, and will update this post at a later date.
UPDATE: I heard back from the PyPy devs on BitBucket, and this is indeed explainable by data transfer between the C-to-PyPy interface. It's probably parallel to the latency that arises from transferring data between the CPU and GPU, or between compute nodes.
So, what does this mean? It means that for pure Python code, PyPy can be a very powerful way to accelerate your code. One example I can imagine is agent-based simulations using Python objects. Another example that comes to mind is running a web server that only ever deals with strings, floats and JSONs (in contrast to matrix-heavy scientific computing).
Now, for those who are curious, here's the source code for the pure Python implementation of the mean of random numbers.
# Mean of 10 million random number draws. from time import time from random import random start = time() n = 1E7 rnds = 0 for i in range(int(n)): rnds += random() print(rnds / n) end = time() print("{} seconds".format(end - start))
And here's the source code for the numpy implementation of the mean of random numbers.
import numpy as np from time import time start = time() mean = np.mean(np.random.random(size=int(1E7))) print(mean) end = time() print('{} seconds'.format(end - start))
Next, here's the source code for coin flips in pure Python:
# Simulate 10 million biased coin flips with p = 0.3 from random import random from time import time from collections import Counter start = time() def bernoulli(p): rnd = random() if rnd < p: return True else: return False p = 0.3 result = [bernoulli(p) for i in range(int(1E7))] print(Counter(result)) end = time() print('{} seconds'.format(end - start))
And finally, source code for coin flips using numpy:
from numpy.random import binomial from time import time from collections import Counter start = time() coinflips = binomial(n=1, p=0.3, size=int(1E7)) end = time() print('Time for numpy coinflips: {} seconds'.format(end - start)) print(Counter(coinflips)) end = time() print('{} seconds'.format(end - start))
Cite this blog post:
@article{
ericmjl-2017-pypy-impressive,
author = {Eric J. Ma},
title = {PyPy: Impressive!},
year = {2017},
month = {10},
day = {11},
howpublished = {\url{https://ericmjl.github.io}},
journal = {Eric J. Ma's Blog},
url = {https://ericmjl.github.io/blog/2017/10/11/pypy-impressive},
}
I send out a newsletter with tips and tools for data scientists. Come check it out at Substack.
If you would like to sponsor the coffee that goes into making my posts, please consider GitHub Sponsors!