Eric J Ma's Website
written by Eric J. Ma on 2024-02-07 | tags: talks conferences slas2024 data science biotech
In this blog post, I shared my insights from the SLAS 2024 conference on how a data science team can deliver long-lasting impact in a biotech research setting. I discussed the importance of bounding work, identifying high-value use cases, possessing technical and interpersonal skills, and having the right surrounding context. I also shared some personal experiences and lessons learned from my work at Moderna. How can these insights help your data science team become successful agents of high-value delivery? Read on to find out!
I spoke this year at the SLAS 2024 conference. The track that I spoke in was the Data Science and Artificial Intelligence track. I'd like to share the contents of that talk here, while also fleshing out additional content that I didn't put in there.
First off, the slides can be found on GitHub pages.
I wanted to answer two key questions with this talk:
- What does it take for a data science team to successfully deliver long-lasting impact through data products?
- How do we do that in a biotech research setting?
For that, there were four key ideas that I shared:
- A framework for bounding work
- Clarity on high-value use cases
- Technical and interpersonal skillsets
- Necessary surrounding context
Behind this is a philosophical stance. I'm not interested in building things that live only for the duration that I'm at a company (or shorter). I'm also not interested in my impact, and my teammates' impact, being measured by how many times we've been acknowledged on a colleagues' internal presentation. I'm most interested in wanting to build lasting solutions that live beyond my duration at a company, so that we have maximum leverage delivered. Once we've got lasting solutions deployed against stable business/research processes, we get to divert our time and energy to more fun and impactful problems instead.
Now, let's talk about each of the four ideas.
Idea 1: Framework for bounding work
Here, I used the example of the DSAI (Research) team at Moderna, where in our team charter, we have a 3x3 matrix that outlines what we work on:
| mRNA | Proteins | LNPs | |
|---|---|---|---|
| AI library design | ✅ | ✅ | ✅ |
| Computer vision | ✅ | ❌ | ✅ |
| Probabilistic models + custom algorithms | ✅ | ✅ | ✅ |
Our work fills 8 out of the 9 cells in that matrix, and we cover that much work with only 5 people. There's a ton of leverage that we have in there because of the ways of working that we've adopted.
Note, however, how there's a distinct lack of certain things that other companies might associate with a data science team:
- Bioinformatics
- Computational chemistry
- mRNA design
- Computational protein structure modelling
We have professional teams that are capable of doing these things. Our colleagues are very clear that the DSAI team doesn't have a primary mandate to do these lines of work. That clarity doesn't necessarily imply that we don't touch some of the tools used by our non-DS colleagues when necessary, for e.g., in protein engineering campaigns, we will bust out AlphaFold + PyMOL when needed. That clarity helps us find appropriate collaborations and places for high value delivery.
Idea 2: Clarity on high-value use cases
We have a framework for defining highest-value use cases.
- Primarily, we look at the trade between a data scientist's time and another team's time.
- Secondarily, it is about new capabilities unlocked for colleagues and their expected value gain.
If there's a request for which we're unable to shape up a sense of value along these two lines, we generally won't work on those. On the other hand, if there is extreme clarity on the value of a line of work from those two lenses, we'll prioritize that line of work.
I'm reminded of a conversation I had with Dave Johnson, in which Dave reminded me of the importance of high value work.
Stephane (Moderna's CEO) once asked me, what's the value here? You've only traded your time for one other person's time. Where's the ROI?
That story has stuck with me ever since.
Along those lines, how does this look like in a biotech research setting, then? What are examples of high value use cases?
I offered three examples:
- Automated chromatography analyses: trading one data scientist's time for many multiples of PhD-trained analytical chemists' time sitting in front of their computers wrangling the Chromeleon software.
- Predictive models used to generate AI-designed molecule libraries: trading one data scientist's time for many multiples of laboratory researchers' time exploring sequence or structure space.
- Quantitative image analysis: unlocking the ability to geometrically quantify on images what we might otherwise qualitatively state.
At its core, we have to think about the value that is being delivered.
Technical and Interpersonal Skillsets
These come back to the five key skillsets that I interview for.
- People skills
- Communication skills
- Scientific domain knowledge
- Software development skills
- Modeling skills
In fact, one may conceive of them as a pyramid:
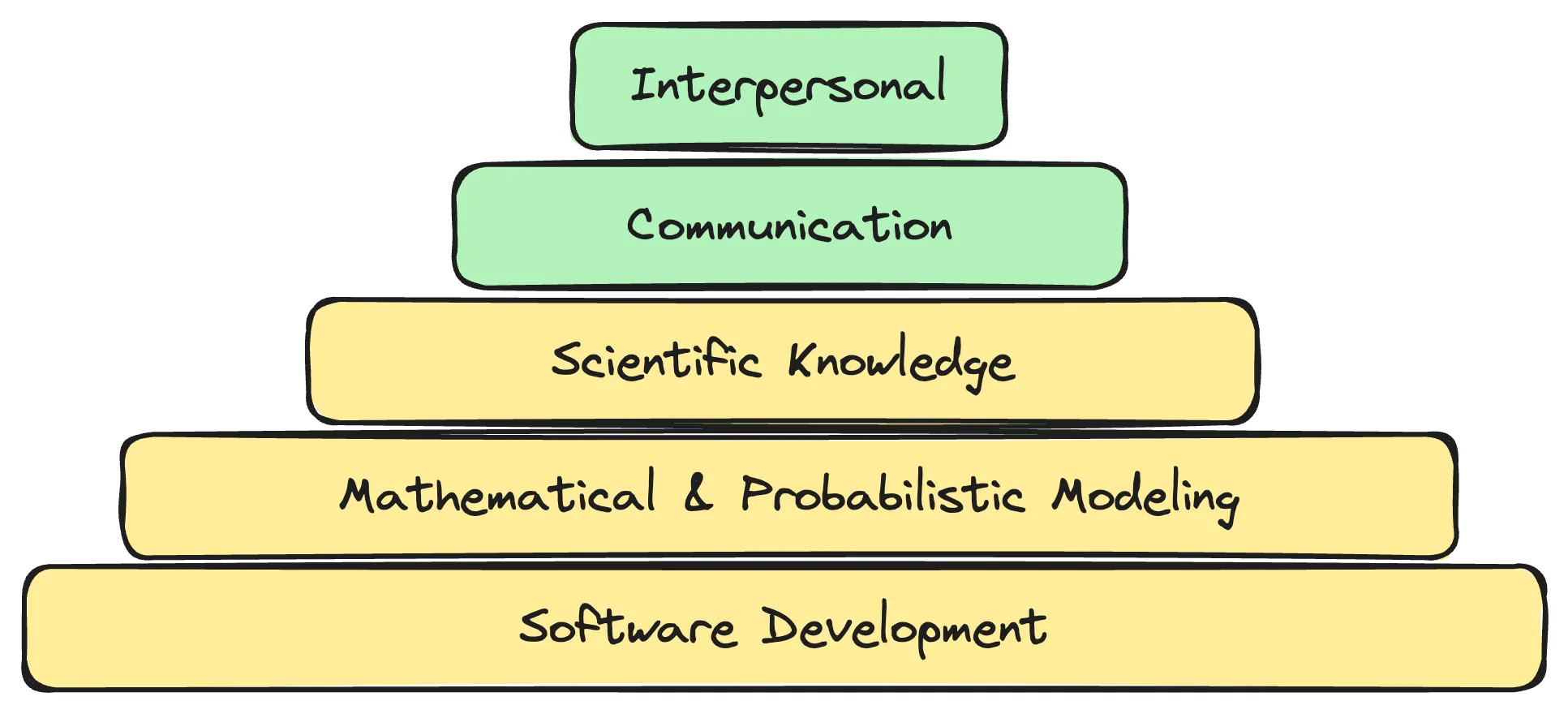
The bottom three are technical foundations that form the base of credibility for our work. The top three are boosters for our credibility in our colleagues' eyes. And credibility is what I'm optimizing for with this criteria. I've written about these criteria before in the essay, "Hiring and Interviewing Data Scientists", but I'll dive into what I mentioned at the talk.
Modelling Skills
With respect to modelling skills,
I am of the conviction that it's insufficient for us to be looking for individuals
who know basic machine learning and have stopped there.
While it's necessary to know scikit-learn, it's insufficient to be a team of scikit-learn monkeys.
Mechanistic modeling is a skillset that I prize,
because we are in a scientific context where mechanistic models are effectively causal models of the systems we're interacting with.
Probabilistic modeling is important because we are dealing with noisy biological systems.
And then having the ability to combine them in a principled way with deep neural networks,
gives us the ability to have neural networks model the nuisance functions (not just nuisance parameters)
with mechanistic equations modeling the important levers that we can control.
Software development skills
The basic skills here are the ability to organize, document, test, and version code. These stem from that core philosophy of building long-lasting solutions that last beyond my tenure at a company. The corollary here is that products (and projects) live long when they are built like well-designed software. If the data science team is to deliver on this, then software development skills are a must-have.
Some teams conceive of their data science teams as being "jupyter notebook prototypers" who then hand stuff off to an engineering team to productionize. And therefore, software development skills are deprioritized. I disagree with this way of working, for three reasons.
Firstly, we are guaranteeing "lost in translation" problems operating this way. Instead, it is much more efficient for delivery to have the data scientist(s) on the team work through the problem and take it to a level of productionization that stops just shy of building user interfaces. The data science team should be owning the creation of APIs for their work that are also end-user accessible in a point-and-click fashion (e.g. FastAPI documentation, or at Moderna, our awesome Compute system). User interfaces, then are what a product + engineering team can focus and specialize on later.
Secondly, I've argued before that software development skills are a research practice. Building a software product while embarking on a project forces clarity on our knowledge in that domain.
Finally, having good software development skills ensures that the work products we build. When we come back to a codebase after a long (> 3 months) hiatus, a well-structured codebase with proper documentation will help us ramp back up faster than if we didn't have that documentation.
Scientific domain knowledge
I noted that within the DSAI (Research) team, we have a minimum requirement that one must have taken graduate-level molecular biology or organic/analytical chemistry classes. Anything less is unacceptable. This stems from our unique situation: we have the privilege of interfacing with PhD-trained chemists and biologists across the organization. If we don't come in with the necessary vocabulary to communicate with them effectively, then we cannot be effective collaborators. This knowledge helps us lubricate communications, helping to build credibility in the eyes of our collaborators.
Communication skills
Communication skills are also supremely important. Our ideas have no use if they stay within our heads. Only when they are communicated skillfully to others can those ideas be turned into reality through execution. We have a high bar for communication, and strive to ensure that everyone's communication skills are top-notch, with the ability to interface upwards/downwards/sideways: to leadership, to teammates, and to peers. Strong communication skills bolsters the credibility of the team.
Interpersonal skills
This is the last piece that we hire for, someone who isn't defensive but willing to accept challenges to their work, who takes pride in their work without harping on their previous accomplishments, who is relentless in up-skilling their knowledge, who is resilient in the face of pressure. High value work often comes with visibility and pressure, so being anti-fragile (and not just resilient) is a huge plus.
Addendum: Isn't this a very high bar?
Through a very productive LinkedIn conversation with Jeffrey Nicholich, I would characterize this hiring bar as being "sufficiently grounded in fundamentals to pick up advanced stuff easily", or perhaps put a different way, finding adaptable individuals with high dynamic range in skillsets and ways of thinking. Check out the comment thread to see more detail if you're curious, or the GitHub gist where I archived the conversation.
Idea 4: The surrounding context
Here, I shared three vignettes from my work about how important it was to have a great supporting context, one that provides a match between your technical and scientific vision for the team.
Story 1: Protein Engineering
I worked with colleagues to build out a full hierarchical Bayesian estimation model for enzyme properties and machine learning models based on the jax-unirep embedding model + random forests. It was 1.5 years of development effort. We were part of an internal startup initiative, had dedicated funding for the effort, had presentations in front of leadership, and even had a paper published!
And then I left, and the intern with whom I was working with back then, Arkadij Kummer, also left.
Two years later, I had a chance to catch up with the project leads. I learned that the work that Arkadij and I did is now dead. Nobody inside Novartis is doing machine learning for their protein engineering campaigns, and they're now working with vendors.
What did we lack? We lacked the technical infrastructure to deploy a closed-loop system for ML + protein engineering. Humans were still needed in the loop. There was no way for this to be made hands-off. The effort was fragile -- depending on humans for the computational workflow. We also lacked the political buy-in to dedicate human time to building out the necessary infrastructure: I was an individual contributor back then and had no clout in the broader Novartis org. I was known as a skilled technical person, but not someone who knew enough about the organization to nudge where it should go.
Story 2: Mouse Motion Analysis
This was another cool model that we built. Together with my colleague Zachary Barry and then-intern Nitin Kumar Mittal, we reverse-engineered a published hierarchical Dirichlet process autoregressive Gaussian hidden Markov model and applied it to mouse motion analysis. The model was super cool, deeply technical. We had plans to open source it.
That effort is dead.
The imaging team that worked on the experimental methods, including my colleague Zach, all left. The need for the model died with the team. We never got to open source the code in time due to other priorities creeping in.
What did we lack? Technical infrastructure aside, the team that we were serving were doing cool science, but it was not yet embedded as part of a core value-generating research process. In some senses, the work we were doing together was on fragile ground -- necessary to prove out the value, but risky. It's a risk anybody in a research organization needs to accept.
Story 3: Computational Design Algorithm
This vignette is much more up-lifting. It comes from my current role at Moderna. One of the earliest efforts I worked on was in collaboration with a team that had made a computational design algorithm that was important to our company. However, it was being run manually as four Jupyter notebooks that were being copied and pasted for each new design request (!), and was a few missing algorithmic pieces that would greatly save a bunch of the algorithm runners' time. The load was getting unbearable for the team handling those design requests: they were roping in computationally-savvy laboratory scientists to do routine designs, and that was an unacceptable use of creative scientists' time!
My first contribution on that effort was to first take that stable algorithm and structure it into a Python package that we then deployed on our internal Compute system - where it runs automatically in the background to this day. My second contribution was to co-develop a companion Python package that did the custom algorithmic work that reduced the time taken to do manual designs that the failed at the automated algorithm. My final contribution was to equip the team that handled those designs with software development practices that enabled them to maintain the algorithm long-term in my absence. Since about 1.5 years ago, I've stopped touching the codebase and instead embarked on alternative collaborations with them, because they are self-sufficient!
What did we have here? I have identified a confluence of the following factors:
- a high value but also stable workflow that needed optimization work,
- buy-in from leadership about the value of the work,
- a team whose role was core to the business function, and
- the same team that was forward-thinking enough to pick up a skill not (then) considered core to their role (software development).
Bonus: Clearly-defined deliverables
Over the time that I have been at Moderna, the Data Science and Artificial Intelligence team (more broadly) has coalesced on the following deliverables as part of our work:
- Version-controlled Python packages that are usable by other computationally savvy individuals.
- Cloud-run CLI tools (that are automatically skinned) for general usage across the company, and
- AI-generated molecule library designs for wet lab teams.
We also train and equip willing colleagues with the same kinds of workflows. They gain the superpower flexibility that we have while also being able to leverage the high-power tooling that we produce for ourselves.
Radical Clarity
To recap, the key ideas that I shared in my talk were:
- A framework for bounding work
- Clarity on high-value use cases
- Technical and interpersonal skillsets
- Necessary surrounding context
With the right kind of work, the right value being generated, by the right people in the right environment, your data science team can be successful agents of high-value delivery as well.
Cite this blog post:
@article{
ericmjl-2024-success-factors-for-data-science-teams-in-biotech,
author = {Eric J. Ma},
title = {Success Factors for Data Science Teams in Biotech},
year = {2024},
month = {02},
day = {07},
howpublished = {\url{https://ericmjl.github.io}},
journal = {Eric J. Ma's Blog},
url = {https://ericmjl.github.io/blog/2024/2/7/success-factors-for-data-science-teams-in-biotech},
}
I send out a newsletter with tips and tools for data scientists. Come check it out at Substack.
If you would like to sponsor the coffee that goes into making my posts, please consider GitHub Sponsors!