Eric J Ma's Website
written by Eric J. Ma on 2025-06-27 | tags: automation python open source llm tooling scaling impact software customization development
In this blog post, I share my journey from dreading slide creation to building DeckBot, a tool that automates the process, and reflect on the power of building your own tools as a data scientist. I discuss how creating custom solutions has empowered me and my teams, scaled our impact, and fostered a culture of innovation. I also highlight the importance of organizational support and the joy of learning through building. Curious how building your own tools can transform your work and mindset? Read on to find out!
On 25 June 2025, I delivered a talk at Data-Driven Pharma, an event organized by Ilya Captain and the namesake Data-Driven Pharma organization. In the run-up to the talk, I had been reflecting on two points:
- I hate making slides, and
- I really love building tools.
To that end, I decided... well, I'm not going to bother with making slides. And I'll build a tool that makes slides for me instead. Hence [DeckBot], which currently lives in a marimo notebook, was born. I started off by telling the crowd how much I hated making slides:
In an age of LLMs and plain .txt, I understand why I have such a disdain for powerpoint: you can't easily automate their creation, there's too much that can be hidden behind a bullet point, and it's just an all-round ineffective media for lasting crystal clear communication. By contrast, Markdown slides are better.
-- Original post link here
And how even Andrej Karpathy laments the absence of an LLM-enabled tool for building slides:
Making slides manually feels especially painful now that you know Cursor for slides should exist but doesn’t.
— Andrej Karpathy (@karpathy) June 6, 2025
Also, my informal poll of the audience revealed that approximately 2/3 of the crowd also hated making slides. Not surprising!
So I decided to take that as a nerdsnipe and actually make DeckBot. After showing the audience (live!) how I can make rando slides for completely nondescript topics, such as, "Why eating well is so important" or "pros and cons of buying a thing", I then proceeded with the real exciting challenge of this talk: to get an LLM to generate my entire slide deck for the actual topic I wanted to talk about, from which I would present. And that topic was, well, "Build your own tools!". I then proceeded to copy/paste in the first draft of this blog post into the notebook, and 1 minute later, I had my slides, from which I presented live.
Below is a writeup of what I actually presented, including a written description of some of the interactions.
My main message to everybody today is this: If you're a data scientist, computational biologist, or software developer, you should learn how to build your own tools. Building your own tools is a liberating endeavor. It injects joy back into your day-to-day work. People were made to be creative creators. Build your own tools.
A flashback from my grad school days
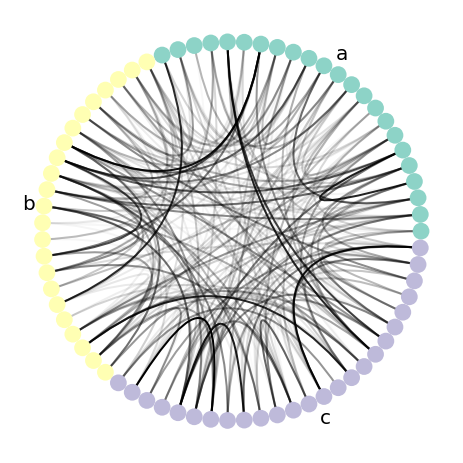
Do you know what this diagram is? The audience came in clutch, many people knew what this was -- it's a Circos plot. Some may have seen it with arcs rather than dots around the edges, but the concept remains the same: prioritize ordering nodes and then draw in the edges.
I wanted to learn how to make a graph visualization like this. But the only tool I saw out there was written in a different language (Perl), had no Python bindings, and was way too complicated for me—a beginner programmer in 2014—to learn. So I decided to leverage two other tools that I knew at the time, Python and matplotlib, to make my own Python package, both to learn software development and to understand the principles of rational network visualization.
The precursor to nxviz, circosplot, was born in 2015. One year later, I knew enough to make all sorts of network visualizations!
Like this, the matrix plot:

Or this, a geo plot:
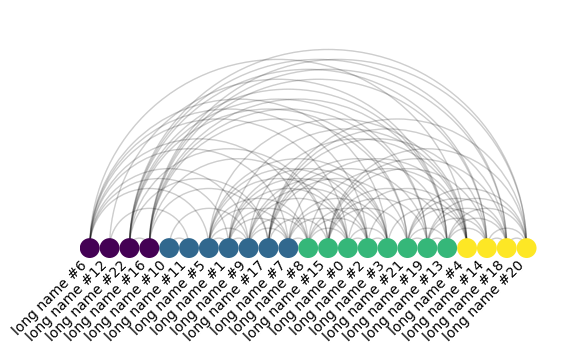
Or this, an arc plot:
Or this, another circos plot:
Or this beautiful thing, a hive plot:
What's the unifying thread behind all of those plots? As it turns out, the thing I learned while building my own graph visualization tool was that rational and beautiful graph visualization starts with knowing how to order nodes in a graph, and then drawing in the edges. I would have never learned that had I not attempted to reinvent the wheel (or, perhaps, Circos plots)! Additionally, being able to build my own Python package was superbly empowering, especially as a graduate student! I could build my own tools, archive them in the public domain, and never have to solve the same problem again. This echoed Simon Willison's approach to software development:
I realized that one of the best things about open source software is that you can solve a problem once and then you can slap an open source license on that solution and you will never have to solve that problem ever again, no matter who's employing you in the future.
It's a sneaky way of solving a problem permanently.
-- Original post link by Simon Willison here
If I didn't know how to build my own tools, I'd have been stuck, and I'd never have learned anything new.
Fast-forward to 2018 at Novartis
My colleague Brant Peterson showed me the R package janitor, and I thought, "Why can't Pythonistas have nice things?"
Then, I remembered Gandhi's admonition
"Be the change you wish to see in the world."
And so, pyjanitor was born.
Your dataframe manipulation and processing code can now be more expressive than native pandas:
df = ( pd.DataFrame.from_dict(company_sales) .remove_columns(["Company1"]) .dropna(subset=["Company2", "Company3"]) .rename_column("Company2", "Amazon") .rename_column("Company3", "Facebook") .add_column("Google", [450.0, 550.0, 800.0]) )
By being the change I wanted to see, Pythonistas now have one more nice thing available to them.
And of course, I just had to inject this in: that was all in 2018.
It's now 2025. Use polars. :)
Building resilience at Moderna
Fast-forward to 2021. I joined Moderna, attracted by the forward-thinking Digital leadership and their suite of high-power home-grown tools. It was a dog-fooding culture back then—one I've fought hard to keep alive within the Digital organization.
Since I was only data scientist #6 at Moderna and was hired into a relatively senior role (Principal Data Scientist), I saw the chance to set standards for Moderna data scientists.
Together with my wonderful colleague Adrianna Loback and our manager Andrew Giessel, we hammered out what Data Scientists would ship: dockerized CLI tools run in the cloud, and Python packages, and designed our entire project initialization workflow around deploying those two things. As time progressed, the tooling evolved, and Dan Luu helped us be a caretaker of the tooling as well, continually improving it and modernizing it.
By standardizing on what we ship and then standardizing on the toolchain, we implemented a design pattern that made it easy for us to help one another. I can jump into a colleague's codebase dealing with Clinical Development and be helpful in a modestly short amount of time, even when I mostly work on Research projects.
And here's a side effect: we designed a portable way of working that works best when you give a Moderna data scientist access to a raw Linux machine. As Andrew Giessel once mentioned to me:
Eventually, tools that abstract away the Linux operating system will fail to satisfy users as they grow up and master Linux. They'll want to jump out of a container and just run raw Linux. Anything that tries to abstract away the filesystem, shell scripts, and more eventually runs into edge cases, so why not just give people access to a raw Linux machine with tools pre-installed?
As it turns out, this evening's other presenter Tommy Tang is also a big fan of the shell:
So now I'm a big fan of giving people access to a raw Linux box, outside of a sandboxed container. Being able to build and run a container is a fundamental skill nowadays—so much so that as a community of data scientists, we've effectively said "no" to vendor tooling that forces us to do our day-to-day work within a Docker container.
And here's the most awesome part: we did this in an "internally open source" fashion. Anyone with a complaint about the tooling can propose a fix to our tools. Even better, we'll walk you through making the fix "the right way," so you gain the superpower of software development along the way!
At least on this dimension, we are never beholden to someone else's (or a vendor's) roadmap! We are now resilient—just like Dustin from Smarter Every Day described when he made this video about trying to make things "in America."
I'll end this section with a huge lesson I've learned during my time working here:
Building teaches you the domain
Do you remember these beautiful graph diagrams from earlier?
Building is a great way to learn new things. Building nxviz helped me learn the principles of graph visualization. Building LlamaBot helped me learn about making LLM applications.
In 2023, I created LlamaBot because I was confused about how to interact with and build LLMs, particularly RAG applications. I decided to turn to my favorite learning tool: building software. This was clarifying—I was forced to encode my understanding into code, and if the code did unexpected things, I knew my understanding was wrong. After all:
Computers are the best students there are. If you teach the computer something wrong, it'll give you back wrong answers. If you design things wrongly, this student will make life hard for you. So you learn to get good at verification.
I've rewritten LlamaBot at least 4 times, each time updating the codebase with the best of my knowledge. Each time round, my understanding improved, and the abstractions changed along with them, and the ergonomics of using LlamaBot got better, more natural. Throughout the changes, some things that have stayed constant:
- The "Bot" analogy, which predates the term "agents," turns out to be a natural way to express Agents.
- The docstore abstraction simplifies storage and retrieval for pure text applications.
- My distaste for writing commit messages and release notes—hence the automated writers for both remain deeply ingrained as dog-fooded tools.
Some things that have evolved:
- QueryBot used to do entire RAG workflows all-in-one—from PDF-to-text conversion to embedding to retrieval. I've since learned it's much better to break those out into separate steps.
- ChatBot used to have a built-in ChatUI. I dropped it because it was too opinionated and unwieldy. Marimo has really good chat UI primitives that should be used instead.
- Inspiration from the
elllibrary:lmb.user("some prompt")orlmb.system("some prompt")for convenient creation of system and user prompts.
In the process of building and designing software, we have to learn the domain so well that we become linguistics experts in that domain. Vocabulary, terms, and their relationships become natural extensions of what we already know. If our code maps to the domain properly, our abstractions become so natural they're self-documenting. If our code maps poorly onto a solid understanding of the problem space, it'll end up being a tangled mess that warrants a rewrite. There's nothing wrong with that! Embrace the need to rewrite—with AI assistance nowadays, the activation energy barriers to building your own tools is dramatically reduced.
Internal tooling requires organizational buy-in
I then made my next point: you want to make sure you have organizational buy-in to any tool building efforts. It's super telling if your line management doesn't agree with you. On the other hand, it's super awesome if someone is going to be hired explicitly for tooling, like at Quora below:
We are opening up a new role at Quora: a single engineer who will use AI to automate manual work across the company and increase employee productivity. I will work closely with this person. pic.twitter.com/iKurWS6W7v
— Adam D'Angelo (@adamdangelo) June 21, 2025

Reading this tweet triggered a thought in my mind: sustaining internal tool builds help with organizational buy-in. Does your organization empower you to build the tools you need to get your work done? I was lucky to have full leadership buy-in through Andrew Giessel and Dave Johnson, and my current manager Wade keeps roadblocks away from innovating on how we work. I also try to encourage this across teams I have influence with, even without direct managerial responsibilities.
But as I also mentioned earlier, even though sustaining an internal tool build can be boosted with organizational buy-in, culture needs no permission. We always have agency. We always have the free will to make things happen. We always can go forth and build. Build the smallest thing that gets roadblocks out of your way and move on. Throwaway builds are OK! No permission required.
Expert practitioners agree: build your own tools
If my arguments don't convince you, perhaps Hamel Husain, one of the leading AI eval practitioners, will:
Build a custom annotation tool. This is the single most impactful investment you can make for your AI evaluation workflow. With AI-assisted development tools like Cursor or Lovable, you can build a tailored interface in hours. I often find that teams with custom annotation tools iterate ~10x faster.
Custom tools excel because:
- They show all your context from multiple systems in one place
- They can render your data in a product-specific way (images, widgets, markdown, buttons, etc.)
- They're designed for your specific workflow (custom filters, sorting, progress bars, etc.)
Off-the-shelf tools may be justified when you need to coordinate dozens of distributed annotators with enterprise access controls. Even then, many teams find the configuration overhead and limitations aren't worth it.
He makes a great point: "With AI-assisted development tools like Cursor or Lovable, you can build a tailored interface in hours."
The barrier to entry for building your own tools nowadays is so much lower than before. Much of the grunt work can be automated away using templating and LLM assistance. If you want to build, now is the time to build.
Software development scales everything
I love the work I do partly because it is in the service of the discovery of medicines, and partly because I have an outlet for expressing creativity through the tools I make for myself and others. Through nearly 10 years of making tools, I've crystallized this lesson in scaling:
- Software scales our labor.
- Documentation scales our brains.
- Tests scale others' trust in our code.
- Design scales our agility.
- Agents scale our processes.
- Open source scales opportunity for impact.
If you can build software tools for yourself, you can scale yourself. If you teach others to use those same tools, you can scale their labor. You can scale your brain by documenting those tools well. If you test those tools thoroughly, you can scale trust in the codebase, enabling others to contribute with confidence. If you design the software well—and more importantly, design the business process that software supports well—you can become nimble and agile without the trappings of Big Fake Agile. If you use agents, and more generally automation as part of the custom tooling, you can scale those same processes even further. If you make your tooling open source (whether internally or externally), you scale the opportunity for others to contribute.
Culture needs no permission (another great lesson that I learned from Andrew Giessel), and if you need to unblock yourself, build your own tools. There is no magic sauce in the choice of tools that we use and make. The magic sauce is in the people who choose to show up and build.
And so, my fellow builders, let's build. Not because your company wants it of you, but because patients are waiting. Patients have no patience. We joined this line of work because we want to have the greatest impact on patients with our medicines. Computational types like should never be the bottleneck to shipping medicines. Building tools for ourselves empowers us to keep ourselves unstuck, remove the viscous traps that slow you down, and keep medicines moving.
I'll now leave you with a final quote, from Michael Jackson's song, Heal the World:
There are people dying, if you care enough for the living, make a better place for you and for me.
— Heal the World (Michael Jackson)
And so to my fellow techies in bio, it's time to build. Thank you.
Reactions
After Tommy's talk, we had another round of networking, which was awesome. I heard some great perspectives. Alper Kucukural, who is both an industry and academia person, mentioned how his students needed to hear the message that they can be empowered to build their own tools, no permission required. Too many get stuck. Students -- learn how to build!
Maciej Pacula also posted his reaction on LinkedIn:
I had a great time at the DataDrivenPharma event at Moderna yesterday. Thanks Ilya Captain, PhD for organizing, and hope you bring more such events to the East Coast!
Eric Ma's talk about building your own tools and using them as a force multiplier not just for yourself but for others resonated deeply.
🎯 Ming "Tommy" Tang's talk about "good enough" reproducibility made the excellent point that sometimes you just need to talk to the lab scientists (what a concept!) and collaborate on common standards.
Appreciated the shout out for GoFigr.io, 🎯 Ming "Tommy" Tang :-)
Thanks Ted Natoli, Colles Price M.S., Ph.D., Sergiusz Wesolowski, Ilya Shlyakhter, Vasant Marur, Alper Kucukural, PhD, James J. Crowley, Gunjan Singh Thakur for the company and conversation.
-- Original post link here
Eric Merle's reaction is below:
A lot is possible when we build the right tools...
Yesterday's DataDrivenPharma event at Moderna completely energized my thinking about exactly that and I'll tell you specifically why.
Eric Ma from Moderna shared something that hit home: "Data scientists should never become bottlenecks in getting medicines to patients who need them." His approach to building custom tools that scale impact, from automated slide generation to standardized project workflows, showed exactly how thoughtful tooling can accelerate discovery. 🎯 Ming "Tommy" Tang from AstraZeneca complemented this perfectly with his presentation on reproducible bioinformatics practices. His insights on proper file naming conventions (how many of us are guilty of having final1, final2, final3 files?), consistent folder structures, and creating reproducible workflows provided the foundation that makes scaling actually possible. You can't build lasting tools without these fundamentals in place.
Both emphasized that that it's not just writing code, but also about building infrastructure. Eric's philosophy around scaling through software combined with Tommy's disciplined approach to reproducibility showed how the right practices can create tools that continue delivering value long after the original builder moves on.
The potential to create AI tools that don't just automate routine tasks but fundamentally change how we approach patient care and drug development feels limitless. Both presentations reinforced that we're now building the infrastructure that could accelerate how quickly life-saving treatments reach patients. The timing feels perfect. We have AI capabilities that can scale impact in ways that weren't possible even two years ago.
Thanks to Ilya Captain, PhD at DataDrivenPharma for organizing this excellent event and to Louise Liu, PhD, MBA from Hill Research for the introduction to Tommy and recommending I attend.
What tools are you building to scale your impact? Curious to hear what others are working on in this space.
PS: Happy to have been able to chat with Eric and Tommy
-- Original post link here
And Patrick Hofmann:
A couple of great talks by Eric Ma and 🎯 Ming "Tommy" Tang at Ilya Captain, PhD’s Data Driven Pharma event last night. Eric made a strong case for data scientists building their own tools. I’m no programmer, but I have dabbled in woodworking and it reminded me of all the jigs I’ve built for various projects.
There are many facets to the ‘buy vs build’ question and here’s one I think often gets overlooked: If an off the shelf solution is available, will it do precisely what you want? Or will you need to conform your project to it? The answer isn’t always clear cut but it’s worth considering when choosing how to allocate your time and resources.
-- Original post link here
Afterwards, in our discussion, Patrick had a great point about the parallel between custom tools and woodworking jigs: you can either make your own jigs or buy them, but if you buy them, you now have to conform your woodworking to the jig, and not the other way around. Little compromises compound against the quality of the final deliverable!
But where is deckbot?
Ok, I bet you're just like me, you hate making slides, and you want to see DeckBot. You can find it linked here as a marimo notebook! To run it, you'll need an OpenAI API key mapped to the OPENAI_API_KEY environment variable. Download the notebook and run this:
OPENAI_API_KEY="sk-your-api-key-here" uvx marimo edit --sandbox /your/path/to/slides_maker.py
And what were the slides you actually presented?
I archived them for posterity here. Enjoy!
Cite this blog post:
@article{
ericmjl-2025-build-your-own-tools,
author = {Eric J. Ma},
title = {Build your own tools!},
year = {2025},
month = {06},
day = {27},
howpublished = {\url{https://ericmjl.github.io}},
journal = {Eric J. Ma's Blog},
url = {https://ericmjl.github.io/blog/2025/6/27/build-your-own-tools},
}
I send out a newsletter with tips and tools for data scientists. Come check it out at Substack.
If you would like to sponsor the coffee that goes into making my posts, please consider GitHub Sponsors!
Finally, I do free 30-minute GenAI strategy calls for teams that are looking to leverage GenAI for maximum impact. Consider booking a call on Calendly if you're interested!