Chapter 4: Hubs
![]()
%load_ext autoreload
%autoreload 2
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
import warnings
warnings.filterwarnings('ignore')
Introduction
from IPython.display import YouTubeVideo
YouTubeVideo(id="-oimHbVDdDA", width=560, height=315)
Because of the relational structure in a graph, we can begin to think about "importance" of a node that is induced because of its relationships to the rest of the nodes in the graph.
Before we go on, let's think about a pertinent and contemporary example.
An example: contact tracing
At the time of writing (April 2020), finding important nodes in a graph has actually taken on a measure of importance that we might not have appreciated before. With the COVID-19 virus spreading, contact tracing has become quite important. In an infectious disease contact network, where individuals are nodes and contact between individuals of some kind are the edges, an "important" node in this contact network would be an individual who was infected who also was in contact with many people during the time that they were infected.
Our dataset: "Sociopatterns"
The dataset that we will use in this chapter is the "sociopatterns network" dataset. Incidentally, it's also about infectious diseases.
Note to readers: We originally obtained the dataset in 2014 from the Konect website. It is unfortunately no longer available. The sociopatterns.org website hosts an edge list of a slightly different format, so it will look different from what we have here.
From the original description on Konect, here is the description of the dataset:
> This network describes the face-to-face behavior of people > during the exhibition INFECTIOUS: STAY AWAY in 2009 > at the Science Gallery in Dublin. > Nodes represent exhibition visitors; > edges represent face-to-face contacts that were active for at least 20 seconds. > Multiple edges between two nodes are possible and denote multiple contacts. > The network contains the data from the day with the most interactions.
To simplify the network, we have represented only the last contact between individuals.
from nams import load_data as cf
G = cf.load_sociopatterns_network()
It is loaded as an undirected graph object:
type(G)
As usual, before proceeding with any analysis, we should know basic graph statistics.
len(G.nodes()), len(G.edges())
A Measure of Importance: "Number of Neighbors"
One measure of importance of a node is the number of neighbors that the node has. What is a neighbor? We will work with the following definition:
> The neighbor of a node is connected to that node by an edge.
Let's explore this concept, using the NetworkX API.
Every NetworkX graph provides a G.neighbors(node) class method,
which lets us query a graph for the number of neighbors
of a given node:
G.neighbors(7)
It returns a generator that doesn't immediately return the exact neighbors list. This means we cannot know its exact length, as it is a generator. If you tried to do:
len(G.neighbors(7))
you would get the following error:
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-13-72c56971d077> in <module>
----> 1 len(G.neighbors(7))
TypeError: object of type 'dict_keyiterator' has no len()
Hence, we will need to cast it as a list in order to know both its length and its members:
list(G.neighbors(7))
In the event that some nodes have an extensive list of neighbors,
then using the dict_keyiterator is potentially a good memory-saving technique,
as it lazily yields the neighbors.
Exercise: Rank-ordering the number of neighbors a node has
Since we know how to get the list of nodes that are neighbors of a given node, try this following exercise:
> Can you create a ranked list of the importance of each individual, based on the number of neighbors they have?
Here are a few hints to help:
- You could consider using a
pandas Series. This would be a modern and idiomatic way of approaching the problem. - You could also consider using Python's
sortedfunction.
from nams.solutions.hubs import rank_ordered_neighbors
#### REPLACE THE NEXT FEW LINES WITH YOUR ANSWER
# answer = rank_ordered_neighbors(G)
# answer
The original implementation looked like the following
from nams.solutions.hubs import rank_ordered_neighbors_original
# rank_ordered_neighbors_original??
And another implementation that uses generators:
from nams.solutions.hubs import rank_ordered_neighbors_generator
# rank_ordered_neighbors_generator??
Generalizing "neighbors" to arbitrarily-sized graphs
The concept of neighbors is simple and appealing, but it leaves us with a slight point of dissatisfaction: it is difficult to compare graphs of different sizes. Is a node more important solely because it has more neighbors? What if it were situated in an extremely large graph? Would we not expect it to have more neighbors?
As such, we need a normalization factor. One reasonable one, in fact, is the number of nodes that a given node could possibly be connected to. By taking the ratio of the number of neighbors a node has to the number of neighbors it could possibly have, we get the degree centrality metric.
Formally defined, the degree centrality of a node (let's call it d) is the number of neighbors that a node has (let's call it n) divided by the number of neighbors it could possibly have (let's call it N):
NetworkX provides a function for us to calculate degree centrality conveniently:
import networkx as nx
import pandas as pd
dcs = pd.Series(nx.degree_centrality(G))
dcs
nx.degree_centrality(G) returns to us a dictionary of key-value pairs,
where the keys are node IDs
and values are the degree centrality score.
To save on output length, I took the liberty of casting it as a pandas Series
to make it easier to display.
Incidentally, we can also sort the series to find the nodes with the highest degree centralities:
dcs.sort_values(ascending=False)
Does the list order look familiar? It should, since the numerator of the degree centrality metric is identical to the number of neighbors, and the denominator is a constant.
Distribution of graph metrics
One important concept that you should come to know is that the distribution of node-centric values can characterize classes of graphs.
What do we mean by "distribution of node-centric values"? One would be the degree distribution, that is, the collection of node degree values in a graph.
Generally, you might be familiar with plotting a histogram to visualize distributions of values, but in this book, we are going to avoid histograms like the plague. I detail a lot of reasons in a blog post I wrote in 2018, but the main points are that:
- It's easier to lie with histograms.
- You get informative statistical information (median, IQR, extremes/outliers) more easily.
Exercise: Degree distribution
In this next exercise, we are going to get practice visualizing these values using empirical cumulative distribution function plots.
I have written for you an ECDF function that you can use already. Its API looks like the following:
x, y = ecdf(list_of_values)
giving you x and y values that you can directly plot.
The exercise prompt is this:
> Plot the ECDF of the degree centrality and degree distributions.
First do it for degree centrality:
from nams.functions import ecdf
from nams.solutions.hubs import ecdf_degree_centrality
#### REPLACE THE FUNCTION CALL WITH YOUR ANSWER
ecdf_degree_centrality(G)
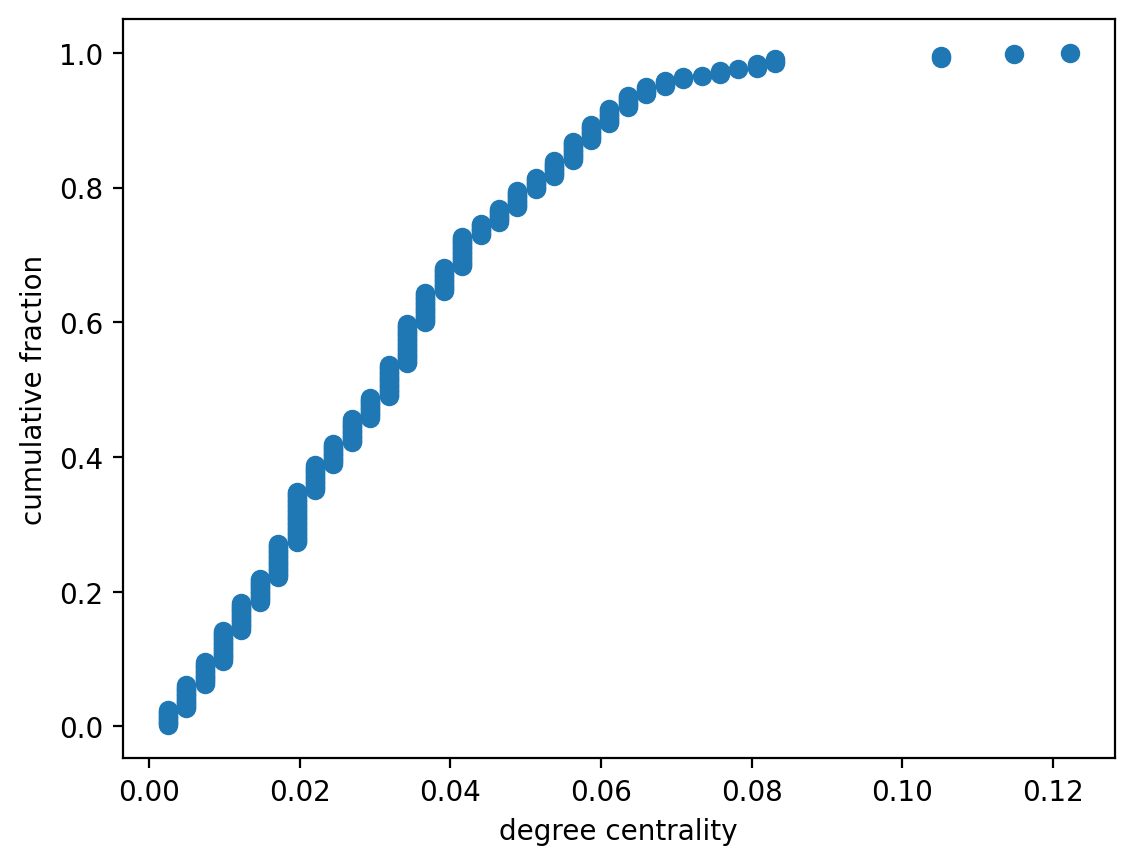
Now do it for degree:
from nams.solutions.hubs import ecdf_degree
#### REPLACE THE FUNCTION CALL WITH YOUR ANSWER
ecdf_degree(G)
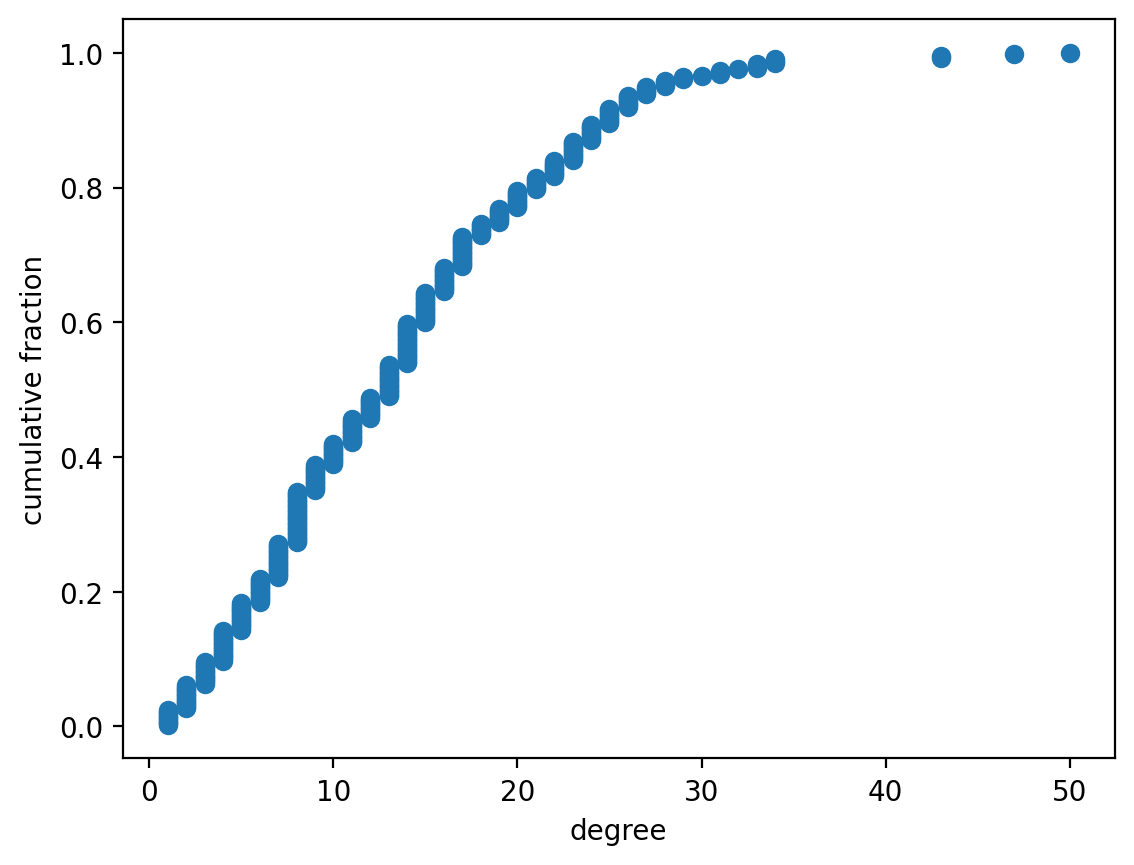
The fact that they are identically-shaped should not surprise you!
Exercise: What about that denominator?
The denominator N in the degree centrality definition is "the number of nodes that a node could possibly be connected to". Can you think of two ways N be defined?
from nams.solutions.hubs import num_possible_neighbors
#### UNCOMMENT TO SEE MY ANSWER
# print(num_possible_neighbors())
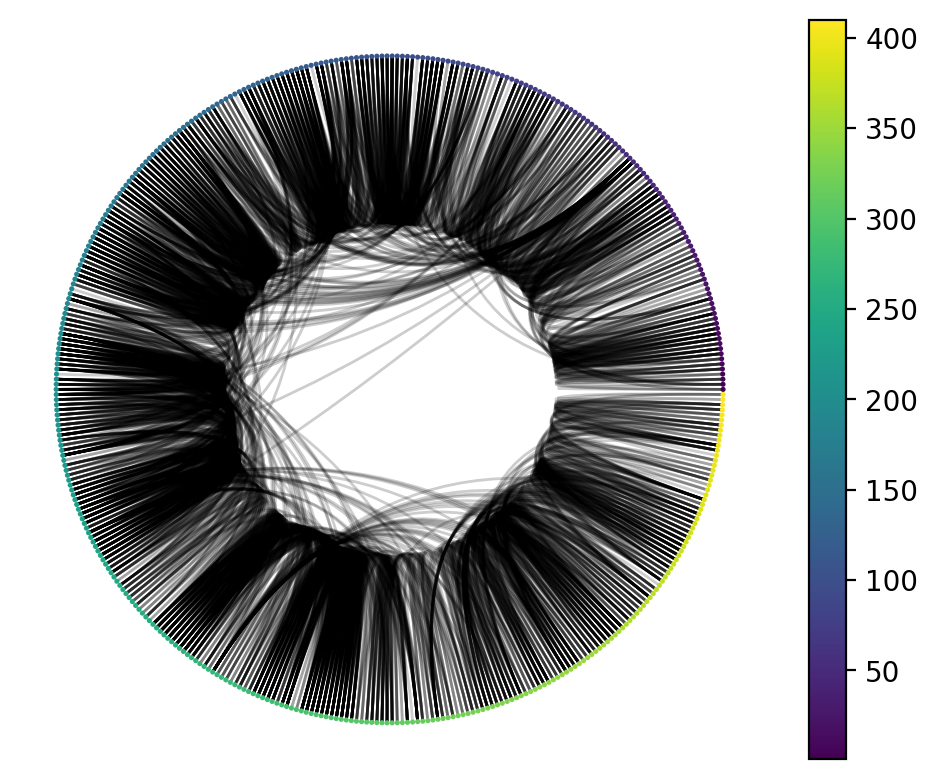
Exercise: Circos Plotting
Let's get some practice with the nxviz API.
> Visualize the graph G, while ordering and colouring them by the 'order' node attribute.
from nams.solutions.hubs import circos_plot
#### REPLACE THE NEXT LINE WITH YOUR ANSWER
circos_plot(G)
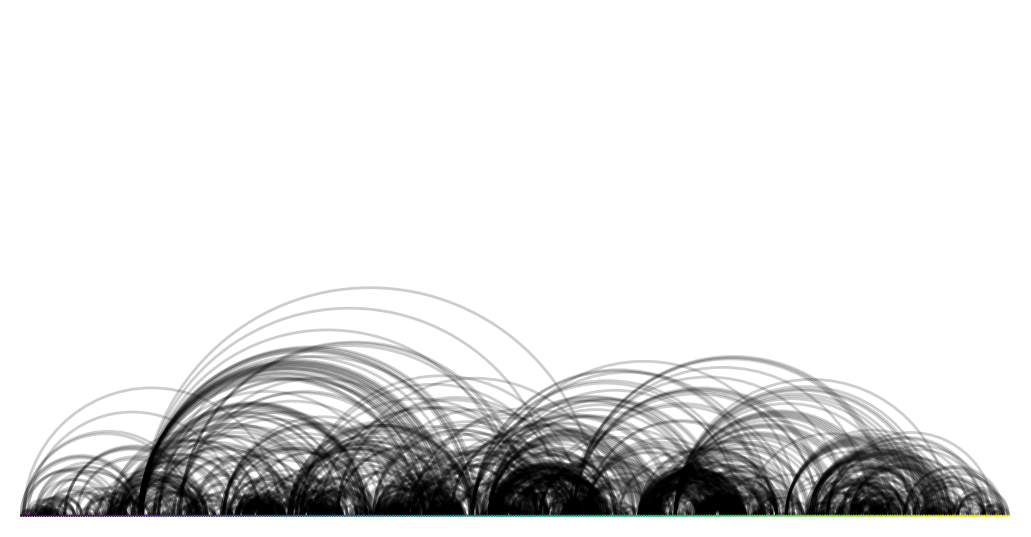
And here's an alternative view using an arc plot.
import nxviz as nv
nv.arc(G, sort_by="order", node_color_by="order")
Exercise: Visual insights
Since we know that node colour and order are by the "order" in which the person entered into the exhibit, what does this visualization tell you?
from nams.solutions.hubs import visual_insights
#### UNCOMMENT THE NEXT LINE TO SEE MY ANSWER
# print(visual_insights())
Exercise: Investigating degree centrality and node order
One of the insights that we might have gleaned from visualizing the graph is that the nodes that have a high degree centrality might also be responsible for the edges that criss-cross the Circos plot. To test this, plot the following:
- x-axis: node degree centrality
- y-axis: maximum difference between the neighbors'
orders (a node attribute) and the node'sorder.
from nams.solutions.hubs import dc_node_order
dc_node_order(G)
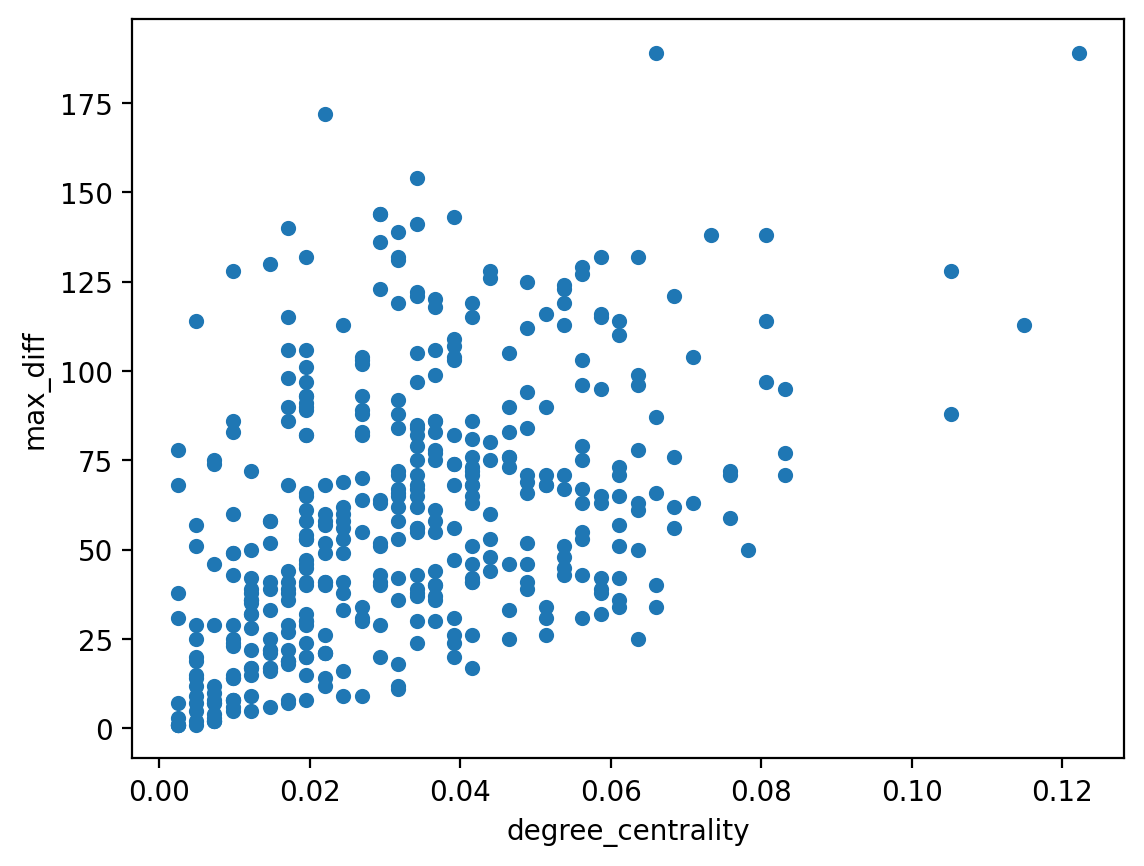
The somewhat positive correlation between the degree centrality might tell us that this trend holds true. A further applied question would be to ask what behaviour of these nodes would give rise to this pattern. Are these nodes actually exhibit staff? Or is there some other reason why they are staying so long? This, of course, would require joining in further information that we would overlay on top of the graph (by adding them as node or edge attributes) before we might make further statements.
Reflections
In this chapter, we defined a metric of node importance: the degree centrality metric. In the example we looked at, it could help us identify potential infectious agent superspreaders in a disease contact network. In other settings, it might help us spot:
- message amplifiers/influencers in a social network, and
- potentially crowded airports that have lots of connections into and out of it (still relevant to infectious disease spread!)
- and many more!
What other settings can you think of in which the number of neighbors that a node has can become a metric of importance for the node?
Solutions
Here are the solutions to the exercises above.
from nams.solutions import hubs
import inspect
print(inspect.getsource(hubs))