Chapter 13: Airport Network
![]()
%load_ext autoreload
%autoreload 2
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
import networkx as nx
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import warnings
warnings.filterwarnings("ignore")
Introduction
In this chapter, we will analyse the evolution of US Airport Network between 1990 and 2015. This dataset contains data for 25 years[1995-2015] of flights between various US airports and metadata about these routes. Taken from Bureau of Transportation Statistics, United States Department of Transportation.
Let's see what can we make out of this!
from nams import load_data as cf
pass_air_data = cf.load_airports_data()
In the pass_air_data dataframe we have the information of number of people that fly every year on a particular route on the list of airlines that fly that route.
pass_air_data.head()
Every row in this dataset is a unique route between 2 airports in United States territory in a particular year. Let's see how many people flew from New York JFK to Austin in 2006.
NOTE: This will be a fun chapter if you are an aviation geek and like guessing airport IATA codes.
jfk_aus_2006 = pass_air_data.query("YEAR == 2006").query(
"ORIGIN == 'JFK' and DEST == 'AUS'"
)
jfk_aus_2006.head()
From the above pandas query we see that according to this dataset 105290 passengers travelled from JFK to AUS in the year 2006.
But how does this dataset translate to an applied network analysis problem? In the previous chapter we created different graph objects for every book. Let's create a graph object which encompasses all the edges.
NetworkX provides us with Multi(Di)Graphs to model networks with multiple edges between two nodes.
In this case every row in the dataframe represents a directed edge between two airports, common sense suggests that if there is a flight from airport A to airport B there should definitely be a flight from airport B to airport A, i.e direction of the edge shouldn't matter. But in this dataset we have data for individual directions (A -> B and B -> A) so we create a MultiDiGraph.
passenger_graph = nx.from_pandas_edgelist(
pass_air_data,
source="ORIGIN",
target="DEST",
edge_key="YEAR",
edge_attr=["PASSENGERS", "UNIQUE_CARRIER_NAME"],
create_using=nx.MultiDiGraph(),
)
We have created a MultiDiGraph object passenger_graph which contains all the information from the dataframe pass_air_data. ORIGIN and DEST represent the column names in the dataframe pass_air_data used to construct the edge. As this is a MultiDiGraph we can also give a name/key to the multiple edges between two nodes and edge_key is used to represent that name and in this graph YEAR is used to distinguish between multiple edges between two nodes. PASSENGERS and UNIQUE_CARRIER_NAME are added as edge attributes which can be accessed using the nodes and the key form the MultiDiGraph object.
Let's check if can access the same information (the 2006 route between JFK and AUS) using our passenger_graph.
To check an edge between two nodes in a Graph we can use the syntax GraphObject[source][target] and further specify the edge attribute using GraphObject[source][target][attribute].
passenger_graph["JFK"]["AUS"][2006]
Now let's use our new constructed passenger graph to look at the evolution of passenger load over 25 years.
# Route betweeen New York-JFK and SFO
values = [
(year, attr["PASSENGERS"]) for year, attr in passenger_graph["JFK"]["SFO"].items()
]
x, y = zip(*values)
plt.plot(x, y)
plt.show()
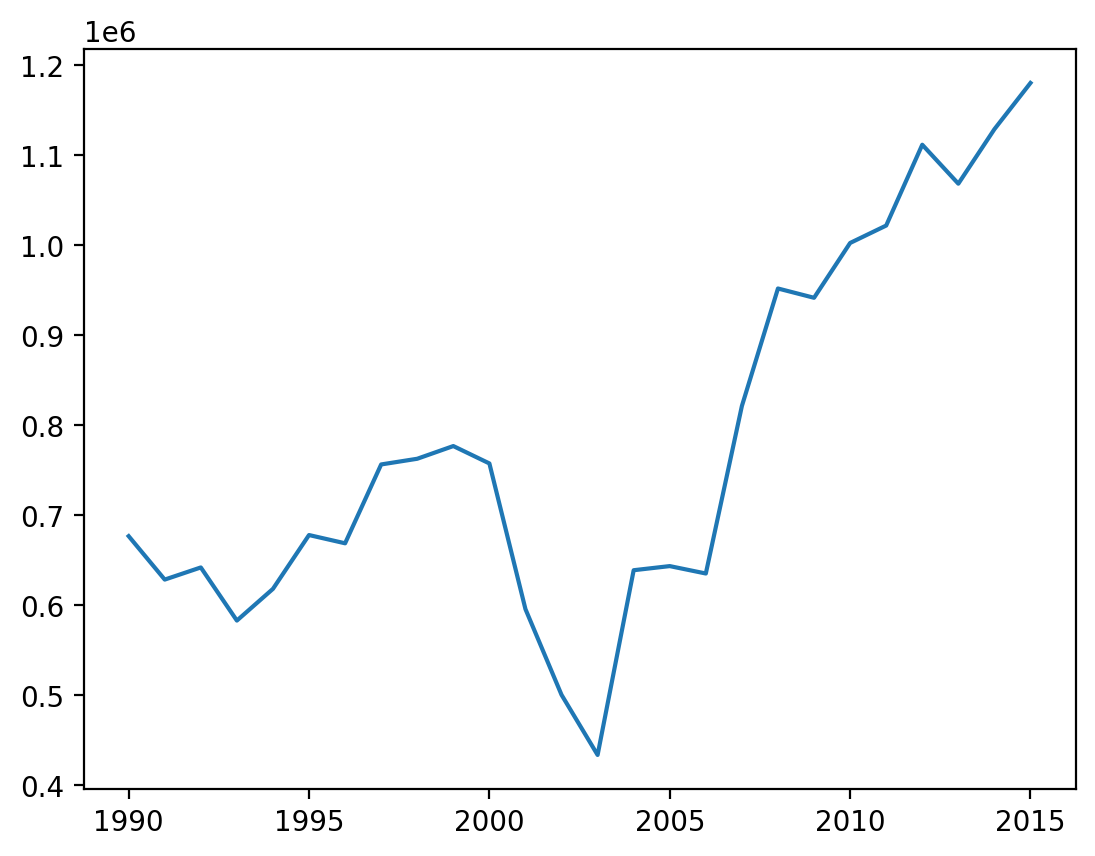
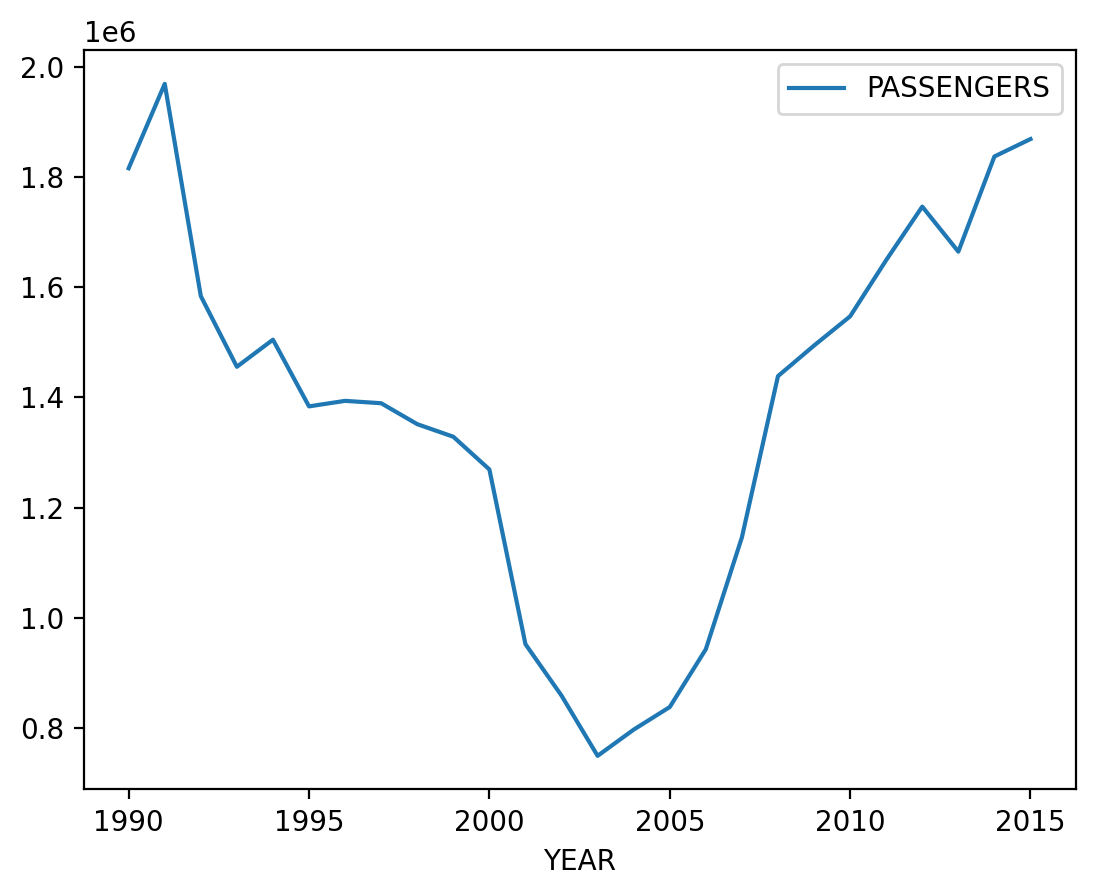
We see some usual trends all across the datasets like steep drops in 2001 (after 9/11) and 2008 (recession).
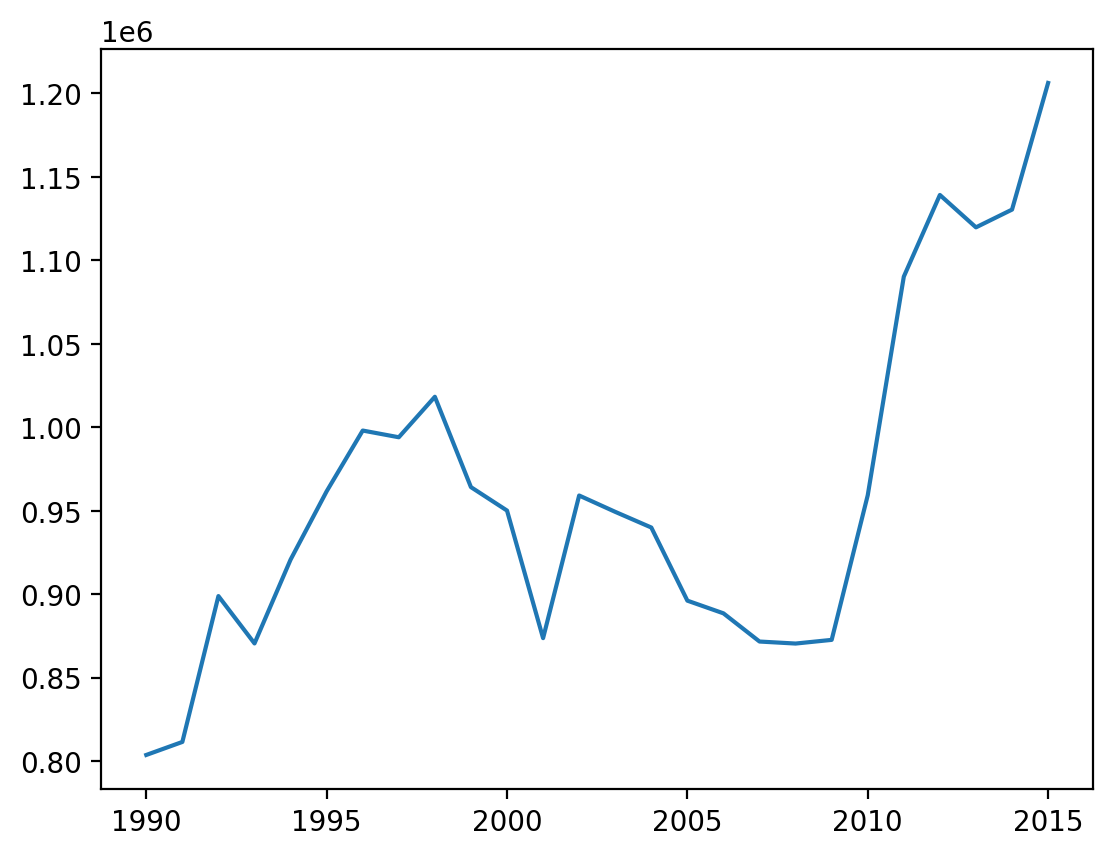
# Route betweeen SFO and Chicago-ORD
values = [
(year, attr["PASSENGERS"]) for year, attr in passenger_graph["SFO"]["ORD"].items()
]
x, y = zip(*values)
plt.plot(x, y)
plt.show()
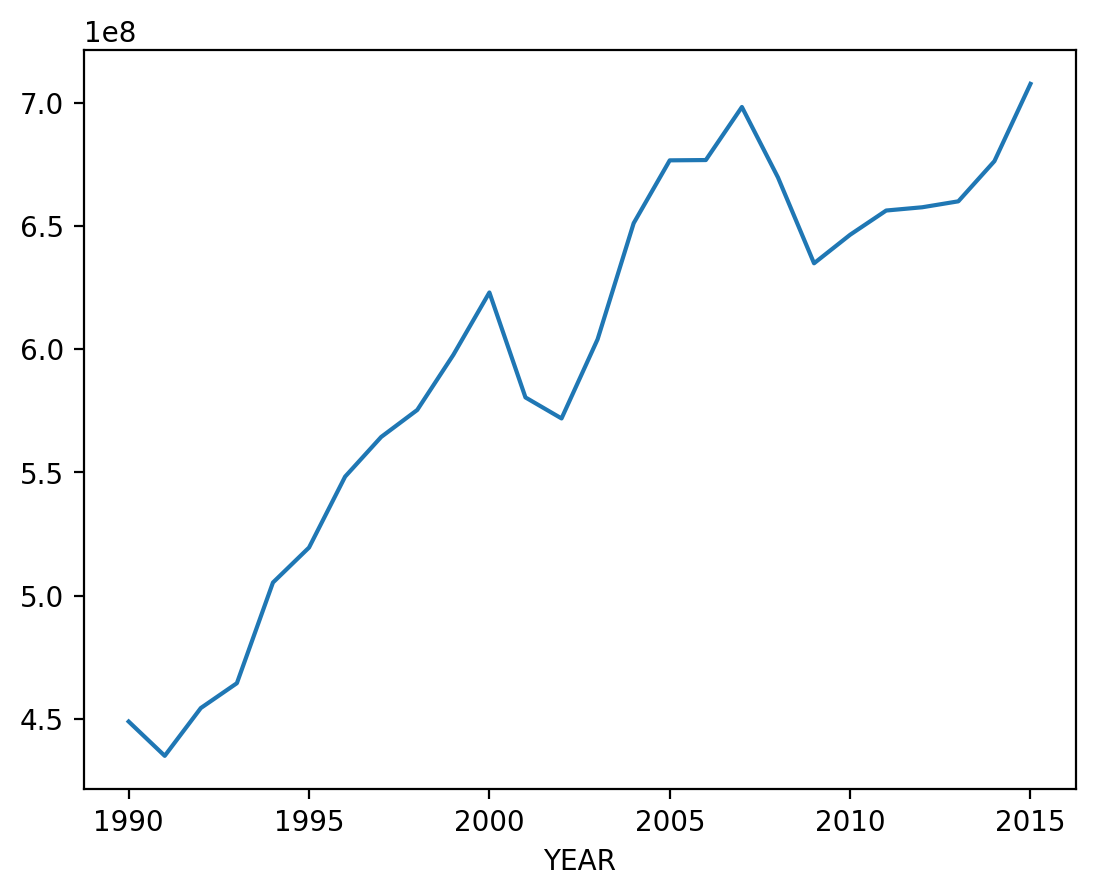
To find the overall trend, we can use our pass_air_data dataframe to calculate total passengers flown in a year.
pass_air_data.groupby(["YEAR"]).sum()["PASSENGERS"].plot()
plt.show()
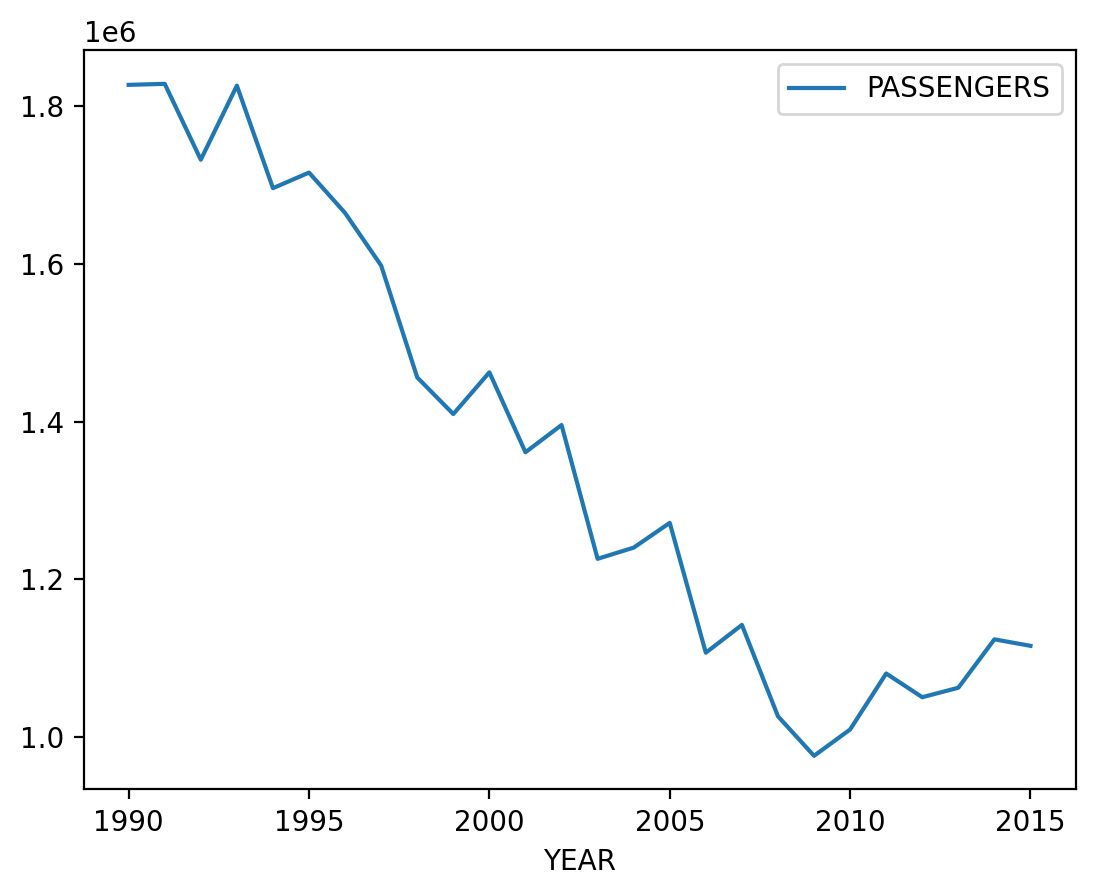
Exercise
Find the busiest route in 1990 and in 2015 according to number of passengers, and plot the time series of number of passengers on these routes.
You can use the DataFrame instead of working with the network. It will be faster :)
from nams.solutions.airport import busiest_route, plot_time_series
busiest_route(pass_air_data, 1990).head()
plot_time_series(pass_air_data, "LAX", "HNL")
busiest_route(pass_air_data, 2015).head()
plot_time_series(pass_air_data, "LAX", "SFO")
Before moving to the next part of the chapter let's create a method to extract edges from passenger_graph for a particular year so we can better analyse the data on a granular scale.
def year_network(G, year):
"""Extract edges for a particular year from
a MultiGraph. The edge is also populated with
two attributes, weight and weight_inv where
weight is the number of passengers and
weight_inv the inverse of it.
"""
year_network = nx.DiGraph()
for edge in G.edges:
source, target, edge_year = edge
if edge_year == year:
attr = G[source][target][edge_year]
year_network.add_edge(
source,
target,
weight=attr["PASSENGERS"],
weight_inv=1 / (attr["PASSENGERS"] if attr["PASSENGERS"] != 0.0 else 1),
airlines=attr["UNIQUE_CARRIER_NAME"],
)
return year_network
pass_2015_network = year_network(passenger_graph, 2015)
# Extracted a Directed Graph from the Multi Directed Graph
# Number of nodes = airports
# Number of edges = routes
print(pass_2015_network)
Visualise the airports
# Loadin the GPS coordinates of all the airports
from nams import load_data as cf
lat_long = cf.load_airports_GPS_data()
lat_long.columns = [
"CODE4",
"CODE3",
"CITY",
"PROVINCE",
"COUNTRY",
"UNKNOWN1",
"UNKNOWN2",
"UNKNOWN3",
"UNKNOWN4",
"UNKNOWN5",
"UNKNOWN6",
"UNKNOWN7",
"UNKNOWN8",
"UNKNOWN9",
"LATITUDE",
"LONGITUDE",
]
lat_long
wanted_nodes = list(pass_2015_network.nodes())
us_airports = (
lat_long.query("CODE3 in @wanted_nodes")
.drop_duplicates(subset=["CODE3"])
.set_index("CODE3")
)
us_airports.head()
# us_airports
# Annotate graph with latitude and longitude
no_gps = []
for n, d in pass_2015_network.nodes(data=True):
try:
pass_2015_network.nodes[n]["longitude"] = us_airports.loc[n, "LONGITUDE"]
pass_2015_network.nodes[n]["latitude"] = us_airports.loc[n, "LATITUDE"]
pass_2015_network.nodes[n]["degree"] = pass_2015_network.degree(n)
# Some of the nodes are not represented
except KeyError:
no_gps.append(n)
# Get subgraph of nodes that do have GPS coords
has_gps = set(pass_2015_network.nodes()).difference(no_gps)
g = pass_2015_network.subgraph(has_gps)
Let's first plot only the nodes, i.e airports. Places like Guam, US Virgin Islands are also included in this dataset as they are treated as domestic airports in this dataset.
import nxviz as nv
from nxviz import nodes, plots, edges
plt.figure(figsize=(20, 9))
pos = nodes.geo(g, encodings_kwargs={"size_scale": 1})
plots.aspect_equal()
plots.despine()

Let's also plot the routes(edges).
import nxviz as nv
from nxviz import nodes, plots, edges, annotate
plt.figure(figsize=(20, 9))
pos = nodes.geo(g, color_by="degree", encodings_kwargs={"size_scale": 1})
edges.line(g, pos, encodings_kwargs={"alpha_scale": 0.1})
annotate.node_colormapping(g, color_by="degree")
plots.aspect_equal()
plots.despine()

Before we proceed further, let's take a detour to briefly discuss directed networks and PageRank.
Directed Graphs and PageRank
The figure below explains the basic idea behind the PageRank algorithm. The "importance" of the node depends on the incoming links to the node, i.e if an "important" node A points towards a node B it will increase the PageRank score of node B, and this is run iteratively. In the given figure, even though node C is only connected to one node it is considered "important" as the connection is to node B, which is an "important" node.
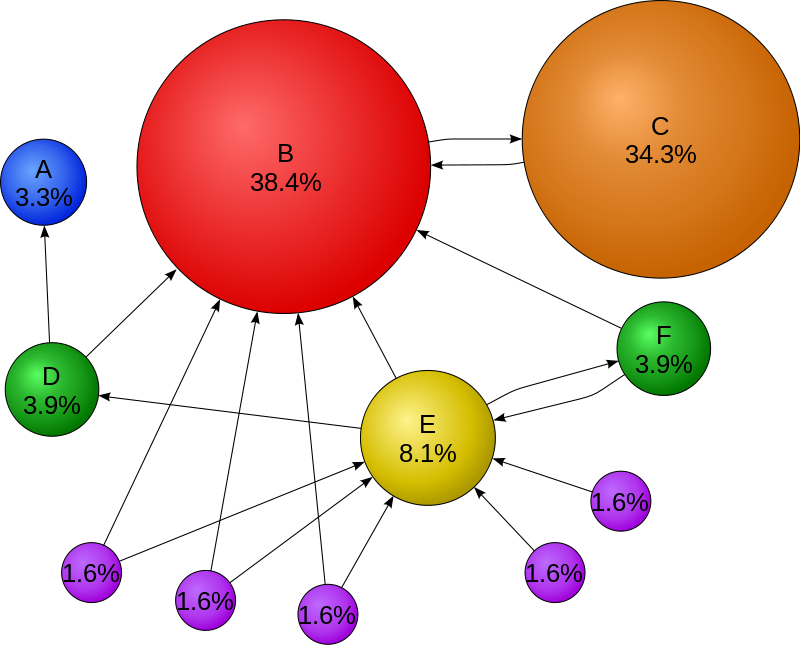
Source: Wikipedia
To better understand this let's work through an example.
# Create an empty directed graph object
G = nx.DiGraph()
# Add an edge from 1 to 2 with weight 4
G.add_edge(1, 2, weight=4)
print(G.edges(data=True))
# Access edge from 1 to 2
G[1][2]
What happens when we try to access the edge from 2 to 1?
G[2][1]
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-137-d6b8db3142ef> in <module>
1 # Access edge from 2 to 1
----> 2 G[2][1]
~/miniconda3/envs/nams/lib/python3.7/site-packages/networkx/classes/coreviews.py in __getitem__(self, key)
52
53 def __getitem__(self, key):
---> 54 return self._atlas[key]
55
56 def copy(self):
KeyError: 1
As expected we get an error when we try to access the edge between 2 to 1 as this is a directed graph.
G.add_edges_from([(1, 2), (3, 2), (4, 2), (5, 2), (6, 2), (7, 2)])
nx.draw_circular(G, with_labels=True)
# nv.circos(G, node_enc_kwargs={"size_scale": 0.3})
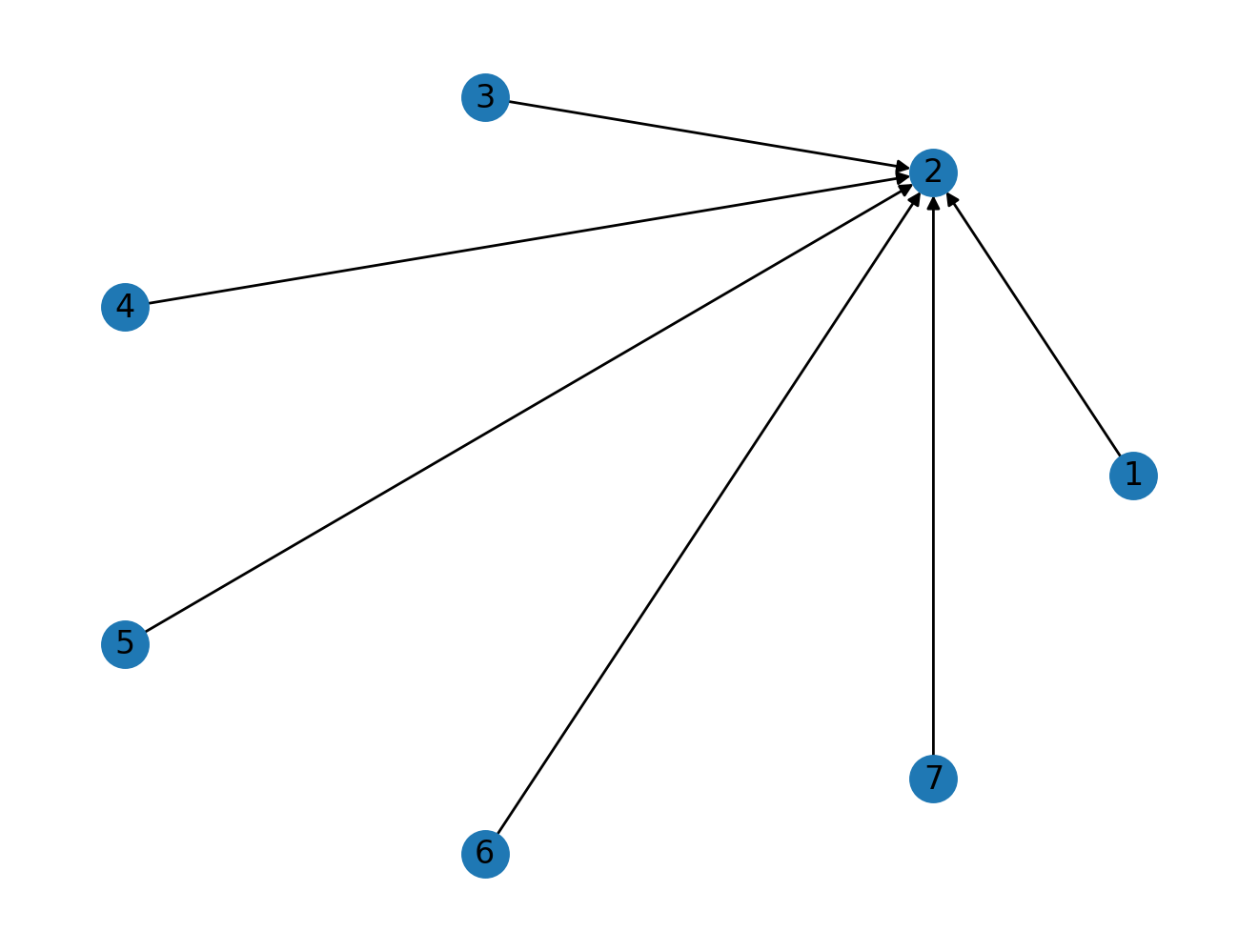
Just by looking at the example above, we can conclude that node 2 should have the highest PageRank score as all the nodes are pointing towards it.
This is confirmed by calculating the PageRank of this graph.
nx.pagerank(G)
What happens when we add an edge from node 5 to node 6.
G.add_edge(5, 6)
# nv.circos(G, node_enc_kwargs={"size_scale": 0.3})
nx.draw_circular(G, with_labels=True)
nx.pagerank(G)
As expected there was some change in the scores (an increase for 6) but the overall trend stays the same, with node 2 leading the pack.
G.add_edge(2, 8)
nx.draw_circular(G, with_labels=True)
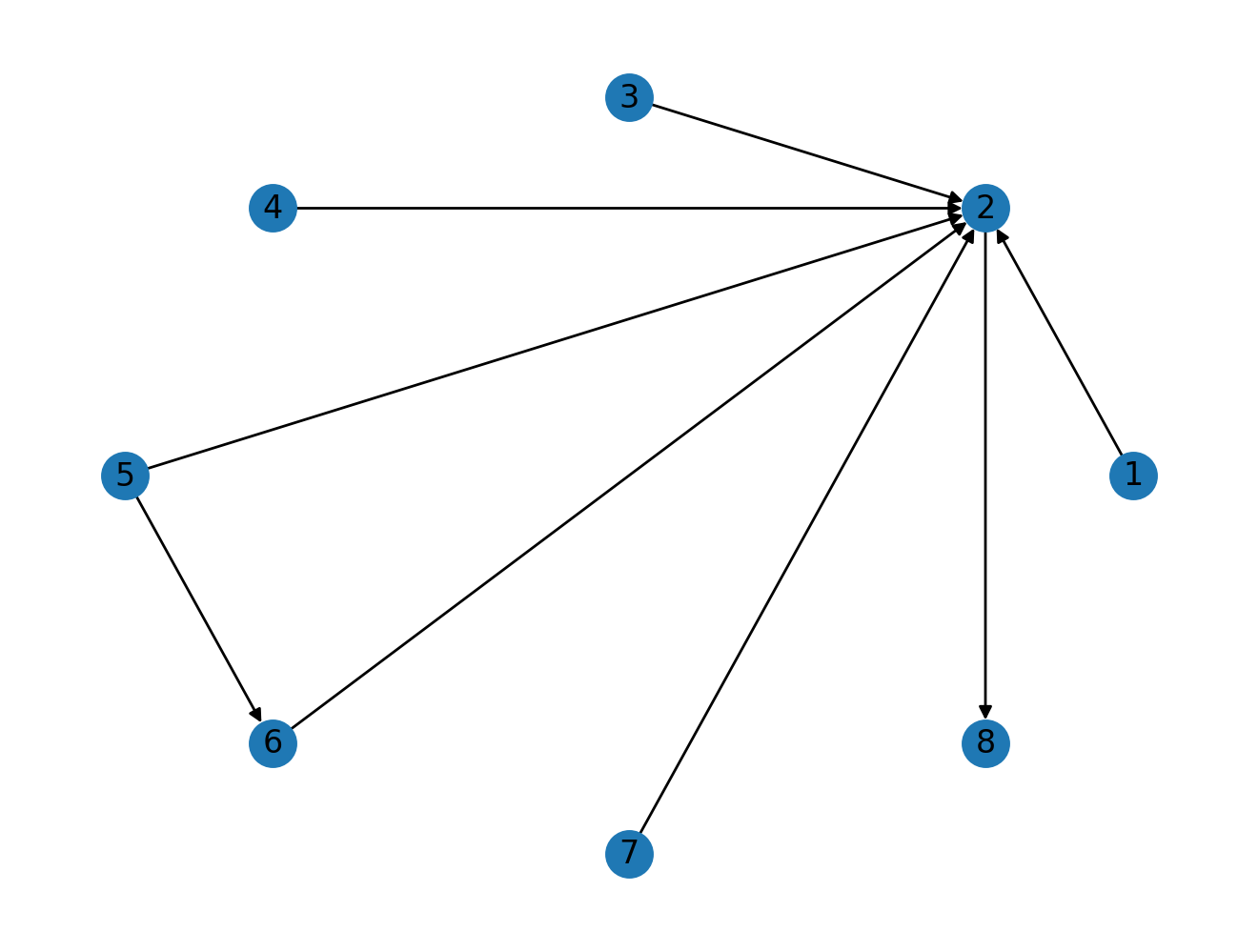
Now we have an added an edge from 2 to a new node 8. As node 2 already has a high PageRank score, this should be passed on node 8. Let's see how much difference this can make.
nx.pagerank(G)
In this example, node 8 is now even more "important" than node 2 even though node 8 has only incoming connection.
Let's move back to Airports and use this knowledge to analyse the network.
Importants Hubs in the Airport Network
So let's have a look at the important nodes in this network, i.e. important airports in this network. We'll use centrality measures like pagerank, betweenness centrality and degree centrality which we gone through in this book.
Let's try to calculate the PageRank of passenger_graph.
nx.pagerank(passenger_graph)
---------------------------------------------------------------------------
NetworkXNotImplemented Traceback (most recent call last)
<ipython-input-144-15a6f513bf9b> in <module>
1 # Let's try to calulate the PageRank measures of this graph.
----> 2 nx.pagerank(passenger_graph)
<decorator-gen-435> in pagerank(G, alpha, personalization, max_iter, tol, nstart, weight, dangling)
~/miniconda3/envs/nams/lib/python3.7/site-packages/networkx/utils/decorators.py in _not_implemented_for(not_implement_for_func, *args, **kwargs)
78 if match:
79 msg = 'not implemented for %s type' % ' '.join(graph_types)
---> 80 raise nx.NetworkXNotImplemented(msg)
81 else:
82 return not_implement_for_func(*args, **kwargs)
NetworkXNotImplemented: not implemented for multigraph type
As PageRank isn't defined for a MultiGraph in NetworkX we need to use our extracted yearly sub networks.
# As pagerank will take weighted measure
# by default we pass in None to make this
# calculation for unweighted network
PR_2015_scores = nx.pagerank(pass_2015_network, weight=None)
# Let's check the PageRank score for JFK
PR_2015_scores["JFK"]
# top 10 airports according to unweighted PageRank
top_10_pr = sorted(PR_2015_scores.items(), key=lambda x: x[1], reverse=True)[:10]
# top 10 airports according to unweighted betweenness centrality
top_10_bc = sorted(
nx.betweenness_centrality(pass_2015_network, weight=None).items(),
key=lambda x: x[1],
reverse=True,
)[0:10]
# top 10 airports according to degree centrality
top_10_dc = sorted(
nx.degree_centrality(pass_2015_network).items(), key=lambda x: x[1], reverse=True
)[0:10]
Before looking at the results do think about what we just calculated and try to guess which airports should come out at the top and be ready to be surprised :D
# PageRank
top_10_pr
# Betweenness Centrality
top_10_bc
# Degree Centrality
top_10_dc
The Degree Centrality results do make sense at first glance, ATL is Atlanta, ORD is Chicago, these are defintely airports one would expect to be at the top of a list which calculates "importance" of an airport. But when we look at PageRank and Betweenness Centrality we have an unexpected airport 'ANC'. Do think about measures like PageRank and Betweenness Centrality and what they calculate. Do note that currently we have used the core structure of the network, no other metadata like number of passengers. These are calculations on the unweighted network.
'ANC' is the airport code of Anchorage airport, a place in Alaska, and according to pagerank and betweenness centrality it is the most important airport in this network. Isn't that weird? Thoughts?
Looks like 'ANC' is essential to the core structure of the network, as it is the main airport connecting Alaska with other parts of US. This explains the high Betweenness Centrality score and there are flights from other major airports to 'ANC' which explains the high PageRank score.
Related blog post: https://toreopsahl.com/2011/08/12/why-anchorage-is-not-that-important-binary-ties-and-sample-selection/
Let's look at weighted version, i.e taking into account the number of people flying to these places.
# Recall from the last chapter we use weight_inv
# while calculating betweenness centrality
sorted(
nx.betweenness_centrality(pass_2015_network, weight="weight_inv").items(),
key=lambda x: x[1],
reverse=True,
)[0:10]
sorted(
nx.pagerank(pass_2015_network, weight="weight").items(),
key=lambda x: x[1],
reverse=True,
)[0:10]
When we adjust for number of passengers we see that we have a reshuffle in the "importance" rankings, and they do make a bit more sense now. According to weighted PageRank, Atlanta, Chicago, Seattle the top 3 airports while Anchorage is at 4th rank now.
To get an even better picture of this we should do the analyse with more metadata about the routes not just the number of passengers.
How reachable is this network?
Let's assume you are the Head of Data Science of an airline and your job is to make your airline network as "connected" as possible.
To translate this problem statement to network science, we calculate the average shortest path length of this network, it gives us an idea about the number of jumps we need to make around the network to go from one airport to any other airport in this network on average.
We can use the inbuilt networkx method average_shortest_path_length to find the average shortest path length of a network.
nx.average_shortest_path_length(pass_2015_network)
---------------------------------------------------------------------------
NetworkXError Traceback (most recent call last)
<ipython-input-157-acfe9bf3572a> in <module>
----> 1 nx.average_shortest_path_length(pass_2015_network)
~/miniconda3/envs/nams/lib/python3.7/site-packages/networkx/algorithms/shortest_paths/generic.py in average_shortest_path_length(G, weight, method)
401 # Shortest path length is undefined if the graph is disconnected.
402 if G.is_directed() and not nx.is_weakly_connected(G):
--> 403 raise nx.NetworkXError("Graph is not weakly connected.")
404 if not G.is_directed() and not nx.is_connected(G):
405 raise nx.NetworkXError("Graph is not connected.")
NetworkXError: Graph is not weakly connected.
Wait, What? This network is not "connected" (ignore the term weakly for the moment). That seems weird. It means that there are nodes which aren't reachable from other set of nodes, which isn't good news in especially a transporation network.
Let's have a look at these far flung airports which aren't reachable.
components = list(nx.weakly_connected_components(pass_2015_network))
# There are 3 weakly connected components in the network.
for c in components:
print(len(c))
# Let's look at the component with 2 and 1 airports respectively.
print(components[1])
print(components[2])
The airports SSB and SPB are codes for Seaplanes airports and they have flights to each other so it makes sense that they aren't connected to the larger network of airports.
The airport is even more weird as it is in a component in itself, i.e there is a flight from AIK to AIK. After investigating further it just seems like an anomaly in this dataset.
AIK_DEST_2015 = pass_air_data[
(pass_air_data["YEAR"] == 2015) & (pass_air_data["DEST"] == "AIK")
]
AIK_DEST_2015.head()
# Let's get rid of them, we don't like them
pass_2015_network.remove_nodes_from(["SPB", "SSB", "AIK"])
# Our network is now weakly connected
nx.is_weakly_connected(pass_2015_network)
# It's not strongly connected
nx.is_strongly_connected(pass_2015_network)
Strongly vs weakly connected graphs.
Let's go through an example to understand weakly and strongly connected directed graphs.
# NOTE: The notion of strongly and weakly exists only for directed graphs.
G = nx.DiGraph()
# Let's create a cycle directed graph, 1 -> 2 -> 3 -> 1
G.add_edge(1, 2)
G.add_edge(2, 3)
G.add_edge(3, 1)
nx.draw(G, with_labels=True)
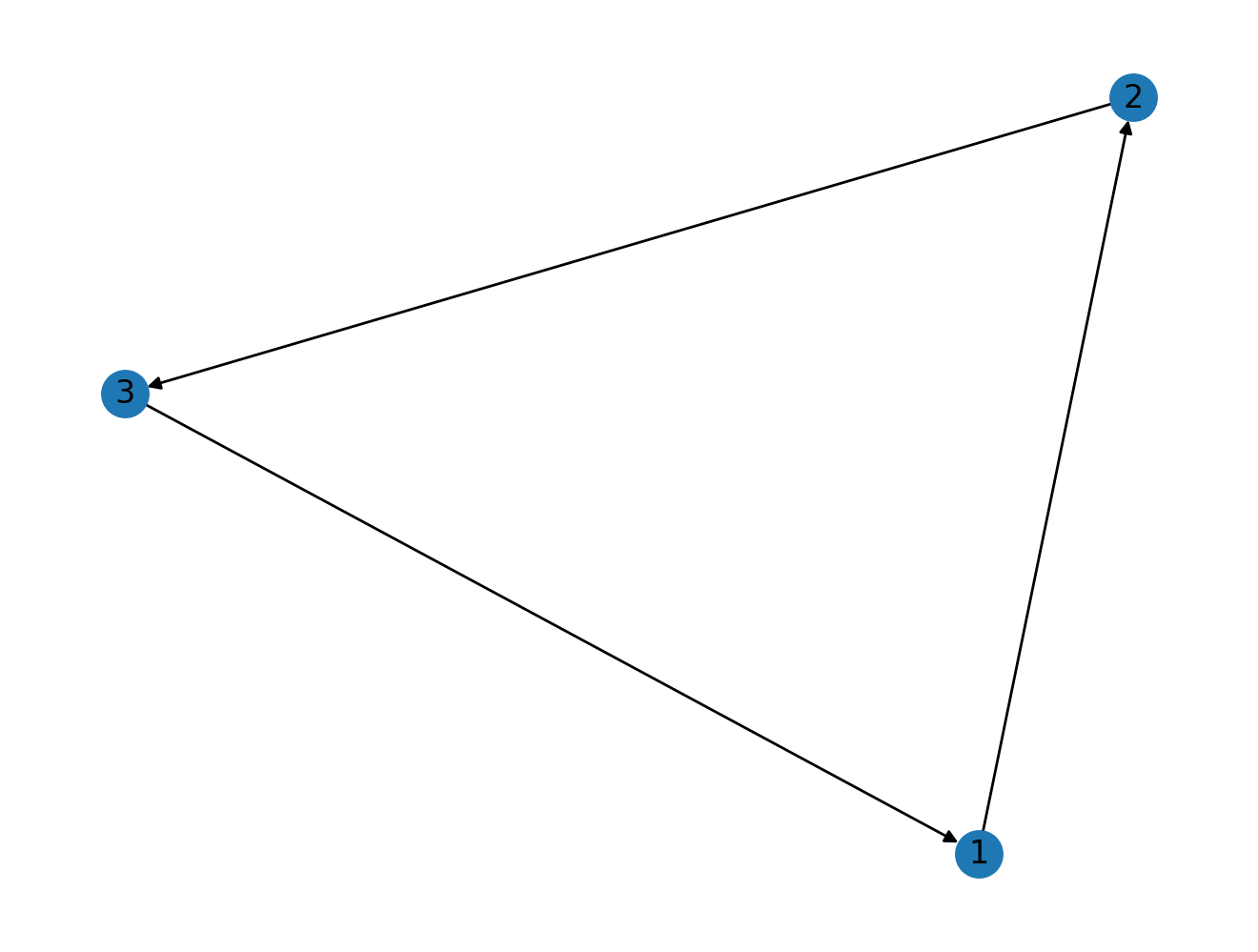
In the above example we can reach any node irrespective of where we start traversing the network, if we start from 2 we can reach 1 via 3. In this network every node is "reachable" from one another, i.e the network is strongly connected.
nx.is_strongly_connected(G)
# Let's add a new connection
G.add_edge(3, 4)
nx.draw(G, with_labels=True)
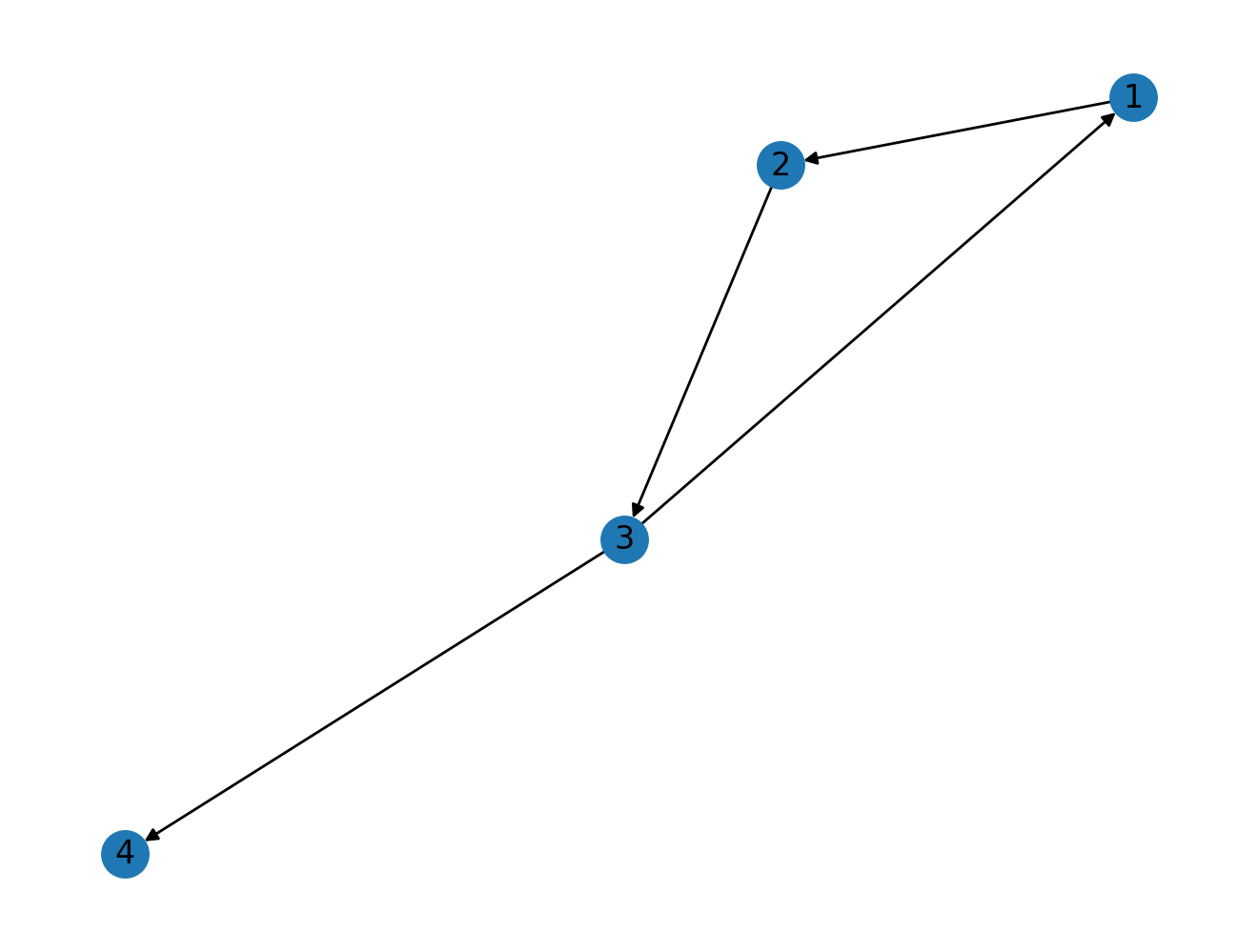
It's evident from the example above that we can't traverse the network graph. If we start from node 4 we are stuck at the node, we don't have any way of leaving node 4. This is assuming we strictly follow the direction of edges. In this case the network isn't strongly connected but if we look at the structure and assume the directions of edges don't matter than we can go to any other node in the network even if we start from node 4.
In the case an undirected copy of directed network is connected we call the directed network as weakly connected.
nx.is_strongly_connected(G)
nx.is_weakly_connected(G)
Let's go back to our airport network of 2015.
After removing those 3 airports the network is weakly connected.
nx.is_weakly_connected(pass_2015_network)
nx.is_strongly_connected(pass_2015_network)
But our network is still not strongly connected, which essentially means there are airports in the network where you can fly into but not fly back, which doesn't really seem okay
strongly_connected_components = list(
nx.strongly_connected_components(pass_2015_network)
)
# Let's look at one of the examples of a strong connected component
strongly_connected_components[0]
bce_2015 = pass_air_data.query("YEAR == 2015").query("ORIGIN == 'BCE' or DEST == 'BCE'")
bce_2015
As we can see above you can fly into BCE but can't fly out, weird indeed. These airport are small airports with one off schedules flights. For the purposes of our analyses we can ignore such airports.
# Let's find the biggest strongly connected component
pass_2015_strong_nodes = max(strongly_connected_components, key=len)
# Create a subgraph with the nodes in the
# biggest strongly connected component
pass_2015_strong = pass_2015_network.subgraph(nodes=pass_2015_strong_nodes)
nx.is_strongly_connected(pass_2015_strong)
After removing multiple airports we now have a strongly connected airport network. We can now travel from one airport to any other airport in the network.
# We started with 1258 airports
len(pass_2015_strong)
nx.average_shortest_path_length(pass_2015_strong)
The 3.17 number above represents the average length between 2 airports in the network which means that it's possible to go from one airport to another in this network under 3 layovers, which sounds nice. A more reachable network is better, not necessearily in terms of revenue for the airline but for social health of the air transport network.
Exercise
How can we decrease the average shortest path length of this network?
Think of an effective way to add new edges to decrease the average shortest path length. Let's see if we can come up with a nice way to do this.
The rules are simple: - You can't add more than 2% of the current edges( ~500 edges)
from nams.solutions.airport import add_opinated_edges
new_routes_network = add_opinated_edges(pass_2015_strong)
nx.average_shortest_path_length(new_routes_network)
Using an opinionated heuristic we were able to reduce the average shortest path length of the network. Check the solution below to understand the idea behind the heuristic, do try to come up with your own heuristics.
Can we find airline specific reachability?
Let's see how we can use the airline metadata to calculate the reachability of a specific airline.
# We have access to the airlines that fly the route in the edge attribute airlines
pass_2015_network["JFK"]["SFO"]
# A helper function to extract the airlines names from the edge attribute
def str_to_list(a):
return a[1:-1].split(", ")
for origin, dest in pass_2015_network.edges():
pass_2015_network[origin][dest]["airlines_list"] = str_to_list(
(pass_2015_network[origin][dest]["airlines"])
)
Let's extract the network of United Airlines from our airport network.
united_network = nx.DiGraph()
for origin, dest in pass_2015_network.edges():
if "'United Air Lines Inc.'" in pass_2015_network[origin][dest]["airlines_list"]:
united_network.add_edge(
origin, dest, weight=pass_2015_network[origin][dest]["weight"]
)
# number of nodes -> airports
# number of edges -> routes
print(united_network)
# Let's find United Hubs according to PageRank
sorted(
nx.pagerank(united_network, weight="weight").items(),
key=lambda x: x[1],
reverse=True,
)[0:5]
# Let's find United Hubs according to Degree Centrality
sorted(nx.degree_centrality(united_network).items(), key=lambda x: x[1], reverse=True)[
0:5
]
Solutions
Here are the solutions to the exercises above.
from nams.solutions import airport
import inspect
print(inspect.getsource(airport))