Chapter 11: Statistical Inference
![]()
%load_ext autoreload
%autoreload 2
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
import warnings
warnings.filterwarnings('ignore')
Introduction
from IPython.display import YouTubeVideo
YouTubeVideo(id="P-0CJpO3spg", width="100%")
In this chapter, we are going to take a look at how to perform statistical inference on graphs.
Statistics refresher
Before we can proceed with statistical inference on graphs, we must first refresh ourselves with some ideas from the world of statistics. Otherwise, the methods that we will end up using may seem a tad weird, and hence difficult to follow along.
To review statistical ideas, let's set up a few statements and explore what they mean.
We are concerned with models of randomness
As with all things statistics, we are concerned with models of randomness. Here, probability distributions give us a way to think about random events and how to assign credibility points to them.
In an abstract fashion...
The supremely abstract way of thinking about a probability distribution is that it is the space of all possibilities of "stuff" with different credibility points distributed amongst each possible "thing".
More concretely: the coin flip
A more concrete example is to consider the coin flip. Here, the space of all possibilities of "stuff" is the set of "heads" and "tails". If we have a fair coin, then we have 0.5 credibility points distributed to each of "heads" and "tails".
Another example: dice rolls
Another concrete example is to consider the six-sided dice. Here, the space of all possibilities of "stuff" is the set of numbers in the range [1, 6]. If we have a fair dice, then we have 1/6 credibility points assigned to each of the numbers. (Unfair dice will have an unequal distribution of credibility points across each face.)
A graph-based example: social networks
If we receive an undirected social network graph with 5 nodes and 6 edges, we have to keep in mind that this graph with 6 edges was merely one of 15 \choose 6 ways to construct 5 node, 6 edge graphs. (15 comes up because there are 15 edges that can be constructed in a 5-node undirected graph.)
Hypothesis Testing
A commonplace task in statistical inferences is calculating the probability of observing a value or something more extreme under an assumed "null" model of reality. This is what we commonly call "hypothesis testing", and where the oft-misunderstood term "p-value" shows up.
Hypothesis testing in coin flips, by simulation
As an example, hypothesis testing in coin flips follows this logic:
- I observe that 8 out of 10 coin tosses give me heads, giving me a probability of heads p=0.8 (a summary statistic).
- Under a "null distribution" of a fair coin, I simulate the distribution of probability of heads (the summary statistic) that I would get from 10 coin tosses.
- Finally, I use that distribution to calculate the probability of observing p=0.8 or more extreme.
Hypothesis testing in graphs
The same protocol applies when we perform hypothesis testing on graphs.
Firstly, we calculate a summary statistic that describes our graph.
Secondly, we propose a null graph model, and calculate our summary statistic under simulated versions of that null graph model.
Thirdly, we look at the probability of observing the summary statistic value that we calculated in step 1 or more extreme, under the assumed graph null model distribution.
Stochastic graph creation models
Since we are going to be dealing with models of randomness in graphs, let's take a look at some examples.
Erdos-Renyi (a.k.a. "binomial") graph
On easy one to study is the Erdos-Renyi graph, also known as the "binomial" graph.
The data generation story here is that we instantiate an undirected graph with n nodes, giving \frac{n^2 - n}{2} possible edges. Each edge has a probability p of being created.
import networkx as nx
G_er = nx.erdos_renyi_graph(n=30, p=0.2)
nx.draw(G_er)
You can verify that there's approximately 20% of \frac{30^2 - 30}{2} = 435.
len(G_er.edges())
len(G_er.edges()) / 435
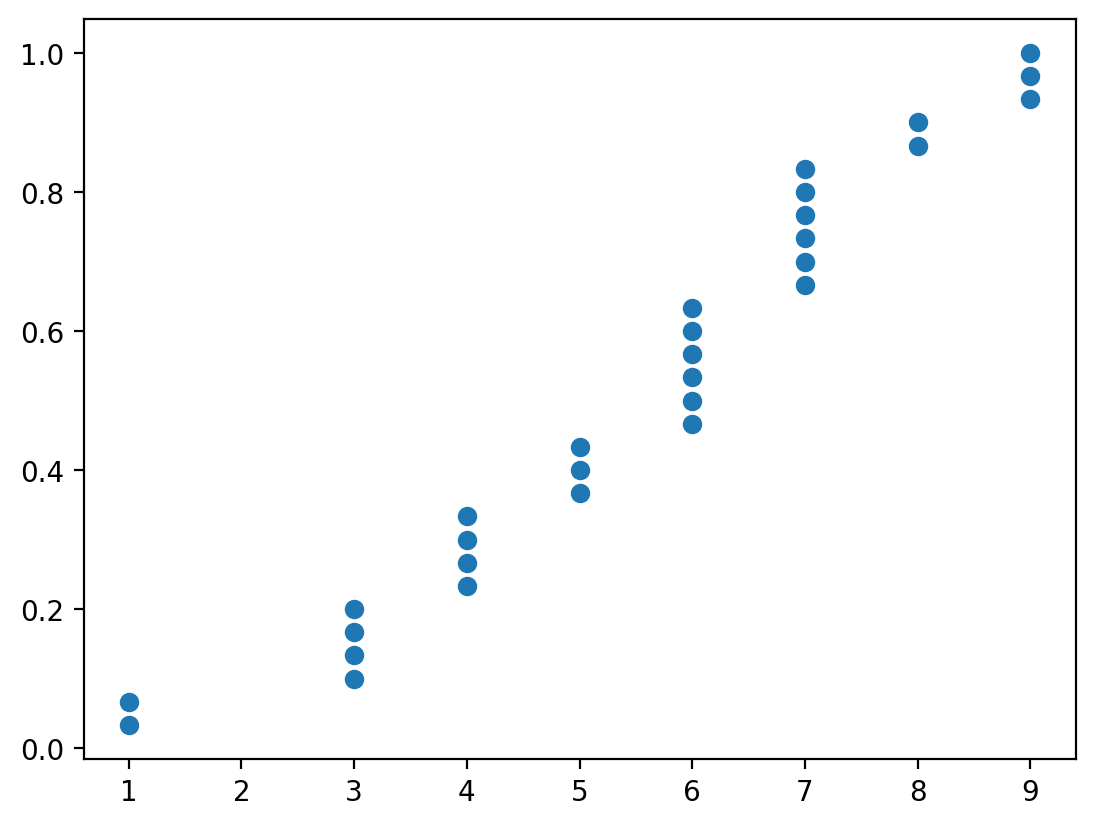
We can also look at the degree distribution:
import pandas as pd
from nams.functions import ecdf
import matplotlib.pyplot as plt
x, y = ecdf(pd.Series(dict(nx.degree(G_er))))
plt.scatter(x, y)
Barabasi-Albert Graph
The data generating story of this graph generator is essentially that nodes that have lots of edges preferentially get new edges attached onto them. This is what we call a "preferential attachment" process.
G_ba = nx.barabasi_albert_graph(n=30, m=3)
nx.draw(G_ba)
len(G_ba.edges())
And the degree distribution:
x, y = ecdf(pd.Series(dict(nx.degree(G_ba))))
plt.scatter(x, y)
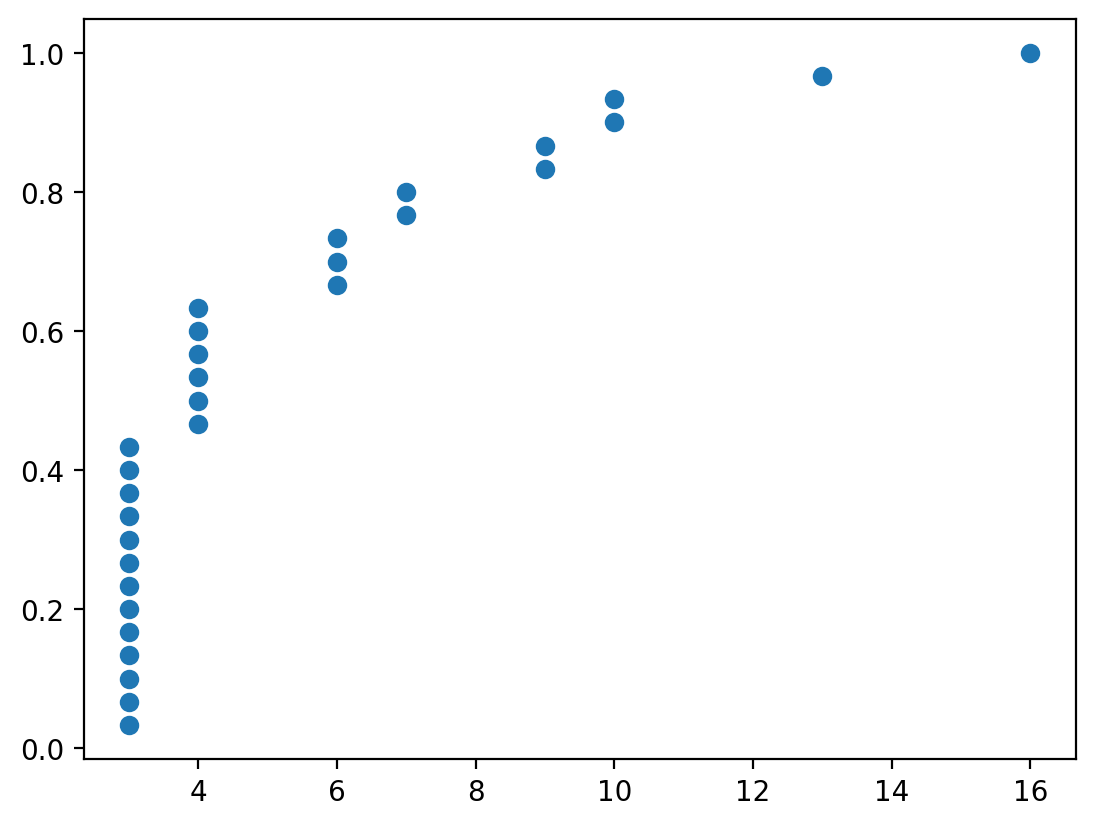
You can see that even though the number of edges between the two graphs are similar, their degree distribution is wildly different.
Load Data
For this notebook, we are going to look at a protein-protein interaction network, and test the hypothesis that this network was not generated by the data generating process described by an Erdos-Renyi graph.
Let's load a protein-protein interaction network dataset.
> This undirected network contains protein interactions contained in yeast. > Research showed that proteins with a high degree > were more important for the surivial of the yeast than others. > A node represents a protein and an edge represents a metabolic interaction between two proteins. > The network contains loops.
from nams import load_data as cf
G = cf.load_propro_network()
for n, d in G.nodes(data=True):
G.nodes[n]["degree"] = G.degree(n)
As is always the case, let's make sure we know some basic stats of the graph.
len(G.nodes())
len(G.edges())
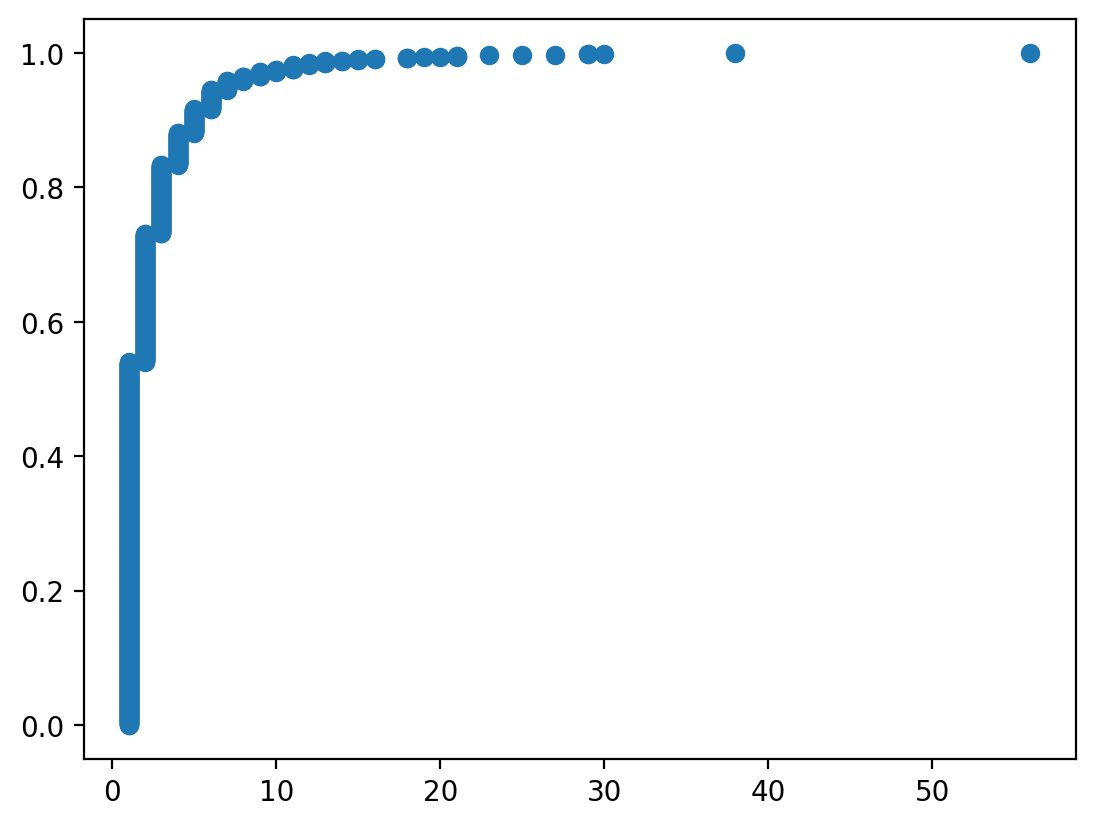
Let's also examine the degree distribution of the graph.
x, y = ecdf(pd.Series(dict(nx.degree(G))))
plt.scatter(x, y)
Finally, we should visualize the graph to get a feel for it.
import nxviz as nv
from nxviz import annotate
nv.circos(
G, sort_by="degree", node_color_by="degree", node_enc_kwargs={"size_scale": 10}
)
annotate.node_colormapping(G, color_by="degree")
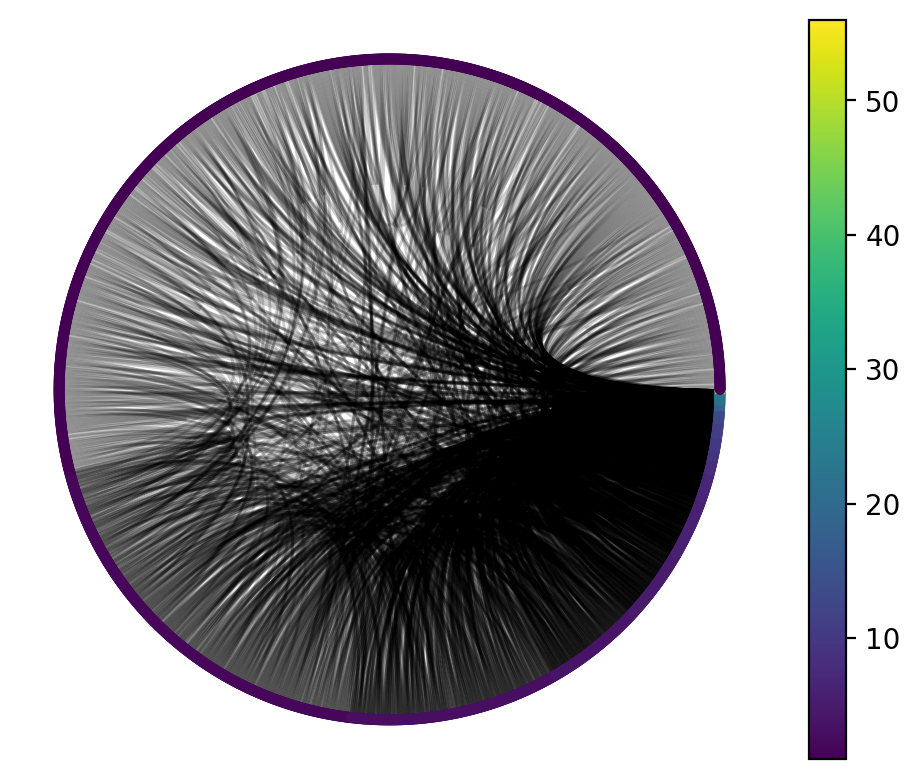
One thing we might infer from this visualization is that the vast majority of nodes have a very small degree, while a very small number of nodes have a high degree. That would prompt us to think: what process could be responsible for generating this graph?
Inferring Graph Generating Model
Given a graph dataset, how do we identify which data generating model provides the best fit?
One way to do this is to compare characteristics of a graph generating model against the characteristics of the graph. The logic here is that if we have a good graph generating model for the data, we should, in theory, observe the observed graph's characteristics in the graphs generated by the graph generating model.
Comparison of degree distribution
Let's compare the degree distribution between the data, a few Erdos-Renyi graphs, and a few Barabasi-Albert graphs.
Comparison with Barabasi-Albert graphs
from ipywidgets import interact, IntSlider
m = IntSlider(value=2, min=1, max=10)
@interact(m=m)
def compare_barabasi_albert_graph(m):
fig, ax = plt.subplots()
G_ba = nx.barabasi_albert_graph(n=len(G.nodes()), m=m)
x, y = ecdf(pd.Series(dict(nx.degree(G_ba))))
ax.scatter(x, y, label="Barabasi-Albert Graph")
x, y = ecdf(pd.Series(dict(nx.degree(G))))
ax.scatter(x, y, label="Protein Interaction Network")
ax.legend()
Comparison with Erdos-Renyi graphs
from ipywidgets import FloatSlider
p = FloatSlider(value=0.6, min=0, max=0.1, step=0.001)
@interact(p=p)
def compare_erdos_renyi_graph(p):
fig, ax = plt.subplots()
G_er = nx.erdos_renyi_graph(n=len(G.nodes()), p=p)
x, y = ecdf(pd.Series(dict(nx.degree(G_er))))
ax.scatter(x, y, label="Erdos-Renyi Graph")
x, y = ecdf(pd.Series(dict(nx.degree(G))))
ax.scatter(x, y, label="Protein Interaction Network")
ax.legend()
ax.set_title(f"p={p}")
Given the degree distribution only, which model do you think better describes the generation of a protein-protein interaction network?
Quantitative Model Comparison
Each time we plug in a value of m for the Barabasi-Albert graph model, we are using one of many possible Barabasi-Albert graph models, each with a different m. Similarly, each time we choose a different p for the Erdos-Renyi model, we are using one of many possible Erdos-Renyi graph models, each with a different p.
To quantitatively compare degree distributions, we can use the Wasserstein distance between the data. Let's see how to implement this.
from scipy.stats import wasserstein_distance
def erdos_renyi_degdist(n, p):
"""Return a Pandas series of degree distribution of an Erdos-Renyi graph."""
G = nx.erdos_renyi_graph(n=n, p=p)
return pd.Series(dict(nx.degree(G)))
def barabasi_albert_degdist(n, m):
"""Return a Pandas series of degree distribution of an Barabasi-Albert graph."""
G = nx.barabasi_albert_graph(n=n, m=m)
return pd.Series(dict(nx.degree(G)))
deg = pd.Series(dict(nx.degree(G)))
er_deg = erdos_renyi_degdist(n=len(G.nodes()), p=0.001)
ba_deg = barabasi_albert_degdist(n=len(G.nodes()), m=1)
wasserstein_distance(deg, er_deg), wasserstein_distance(deg, ba_deg)
Notice that because the graphs are instantiated in a non-deterministic fashion, re-running the cell above will give you different values for each new graph generated.
Let's now plot the wasserstein distance to our graph data for the two particular Erdos-Renyi and Barabasi-Albert graph models shown above.
import matplotlib.pyplot as plt
from tqdm.autonotebook import tqdm
er_dist = []
ba_dist = []
for _ in tqdm(range(100)):
er_deg = erdos_renyi_degdist(n=len(G.nodes()), p=0.001)
er_dist.append(wasserstein_distance(deg, er_deg))
ba_deg = barabasi_albert_degdist(n=len(G.nodes()), m=1)
ba_dist.append(wasserstein_distance(deg, ba_deg))
# er_degs = [erdos_renyi_degdist(n=len(G.nodes()), p=0.001) for _ in range(100)]
import seaborn as sns
import janitor
data = (
pd.DataFrame(
{
"Erdos-Renyi": er_dist,
"Barabasi-Albert": ba_dist,
}
)
.melt(value_vars=["Erdos-Renyi", "Barabasi-Albert"])
.rename_columns({"variable": "Graph Model", "value": "Wasserstein Distance"})
)
sns.swarmplot(data=data, x="Graph Model", y="Wasserstein Distance")
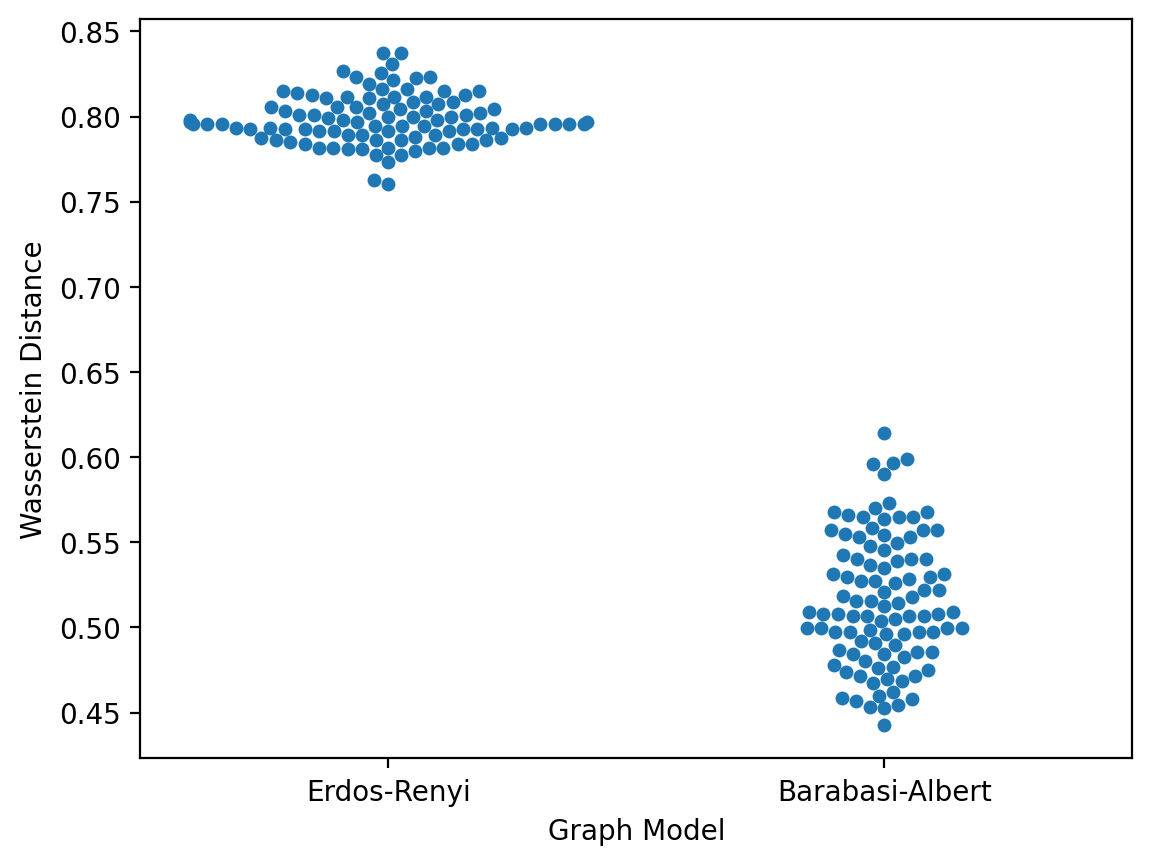
From this, we might conclude that the Barabasi-Albert graph with m=1 has the better fit to the protein-protein interaction network graph.
Interpretation
That statement, accurate as it might be, still does not connect the dots to biology.
Let's think about the generative model for this graph. The Barabasi-Albert graph gives us a model for "rich gets richer". Given the current state of the graph, if we want to add a new edge, we first pick a node with probability proportional to the number of edges it already has. Then, we pick another node with probability proportional to the number of edges that it has too. Finally, we add an edge there. This has the effect of "enriching" nodes that have a large number of edges with more edges.
How might this connect to biology?
We can't necessarily provide a concrete answer, but this model might help raise new hypotheses.
For example, if protein-protein interactions of the "binding" kind are driven by subdomains, then proteins that acquire a domain through recombination may end up being able to bind to everything else that the domain was able to. In this fashion, proteins with that particular binding domain gain new edges more readily.
Testing these hypotheses would be a totally different matter, and at this point, I submit the above hypothesis with a large amount of salt thrown over my shoulder. In other words, the hypothesized mechanism could be completely wrong. However, I hope that this example illustrated that the usage of a "graph generative model" can help us narrow down hypotheses about the observed world.