Chapter 12: Game of Thrones
![]()
%load_ext autoreload
%autoreload 2
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
import pandas as pd
import networkx as nx
import community
import numpy as np
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
Introduction
In this chapter, we will use Game of Thrones as a case study to practice our newly learnt skills of network analysis.
It is suprising right? What is the relationship between a fatansy TV show/novel and network science or Python(not dragons).
If you haven't heard of Game of Thrones, then you must be really good at hiding. Game of Thrones is a hugely popular television series by HBO based on the (also) hugely popular book series A Song of Ice and Fire by George R.R. Martin. In this notebook, we will analyze the co-occurrence network of the characters in the Game of Thrones books. Here, two characters are considered to co-occur if their names appear in the vicinity of 15 words from one another in the books.
The figure below is a precusor of what we will analyse in this chapter.
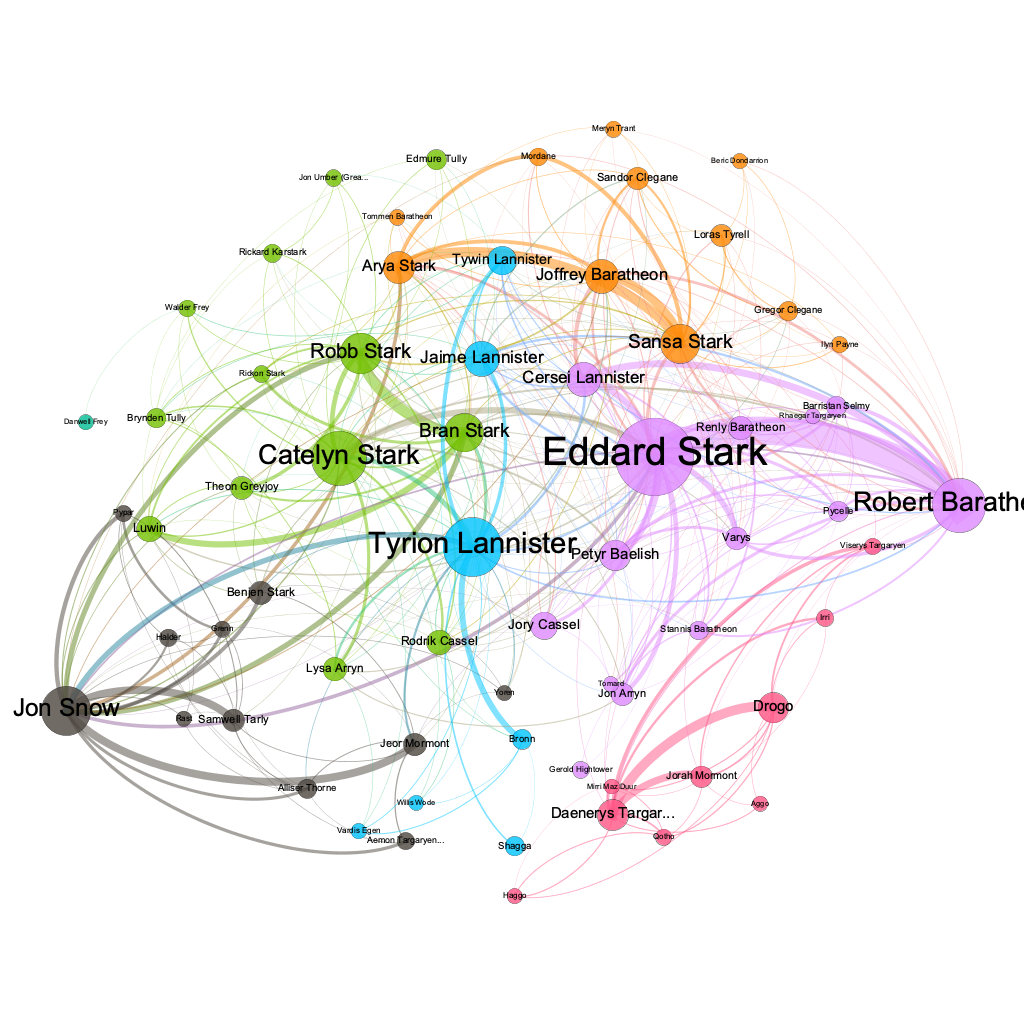
The dataset is publicly avaiable for the 5 books at https://github.com/mathbeveridge/asoiaf. This is an interaction network and were created by connecting two characters whenever their names (or nicknames) appeared within 15 words of one another in one of the books. The edge weight corresponds to the number of interactions.
Blog: https://networkofthrones.wordpress.com
from nams import load_data as cf
books = cf.load_game_of_thrones_data()
The resulting DataFrame books has 5 columns: Source, Target, Type, weight, and book. Source and target are the two nodes that are linked by an edge. As we know a network can have directed or undirected edges and in this network all the edges are undirected. The weight attribute of every edge tells us the number of interactions that the characters have had over the book, and the book column tells us the book number.
Let's have a look at the data.
# We also add this weight_inv to our dataset.
# Why? we will discuss it in a later section.
books["weight_inv"] = 1 / books.weight
books.head()
From the above data we can see that the characters Addam Marbrand and Tywin Lannister have interacted 6 times in the first book.
We can investigate this data by using the pandas DataFrame. Let's find all the interactions of Robb Stark in the third book.
robbstark = books.query("book == 3").query(
"Source == 'Robb-Stark' or Target == 'Robb-Stark'"
)
robbstark.head()
As you can see this data easily translates to a network problem. Now it's time to create a network.
We create a graph for each book. It's possible to create one MultiGraph(Graph with multiple edges between nodes) instead of 5 graphs, but it is easier to analyse and manipulate individual Graph objects rather than a MultiGraph.
# example of creating a MultiGraph
# all_books_multigraph = nx.from_pandas_edgelist(
# books, source='Source', target='Target',
# edge_attr=['weight', 'book'],
# create_using=nx.MultiGraph)
# we create a list of graph objects using
# nx.from_pandas_edgelist and specifying
# the edge attributes.
graphs = [
nx.from_pandas_edgelist(
books[books.book == i],
source="Source",
target="Target",
edge_attr=["weight", "weight_inv"],
)
for i in range(1, 6)
]
# The Graph object associated with the first book.
graphs[0]
# To access the relationship edges in the graph with
# the edge attribute weight data (data=True)
relationships = list(graphs[0].edges(data=True))
relationships[0:3]
Finding the most important node i.e character in these networks.
Let's use our network analysis knowledge to decrypt these Graphs that we have just created.
Is it Jon Snow, Tyrion, Daenerys, or someone else? Let's see! Network Science offers us many different metrics to measure the importance of a node in a network as we saw in the first part of the tutorial. Note that there is no "correct" way of calculating the most important node in a network, every metric has a different meaning.
First, let's measure the importance of a node in a network by looking at the number of neighbors it has, that is, the number of nodes it is connected to. For example, an influential account on Twitter, where the follower-followee relationship forms the network, is an account which has a high number of followers. This measure of importance is called degree centrality.
Using this measure, let's extract the top ten important characters from the first book (graphs[0]) and the fifth book (graphs[4]).
NOTE: We are using zero-indexing and that's why the graph of the first book is acceseed by graphs[0].
# We use the in-built degree_centrality method
deg_cen_book1 = nx.degree_centrality(graphs[0])
deg_cen_book5 = nx.degree_centrality(graphs[4])
degree_centrality returns a dictionary and to access the results we can directly use the name of the character.
deg_cen_book1["Daenerys-Targaryen"]
Top 5 important characters in the first book according to degree centrality.
# The following expression sorts the dictionary by
# degree centrality and returns the top 5 from a graph
sorted(deg_cen_book1.items(), key=lambda x: x[1], reverse=True)[0:5]
Top 5 important characters in the fifth book according to degree centrality.
sorted(deg_cen_book5.items(), key=lambda x: x[1], reverse=True)[0:5]
To visualize the distribution of degree centrality let's plot a histogram of degree centrality.
plt.hist(deg_cen_book1.values(), bins=30)
plt.show()
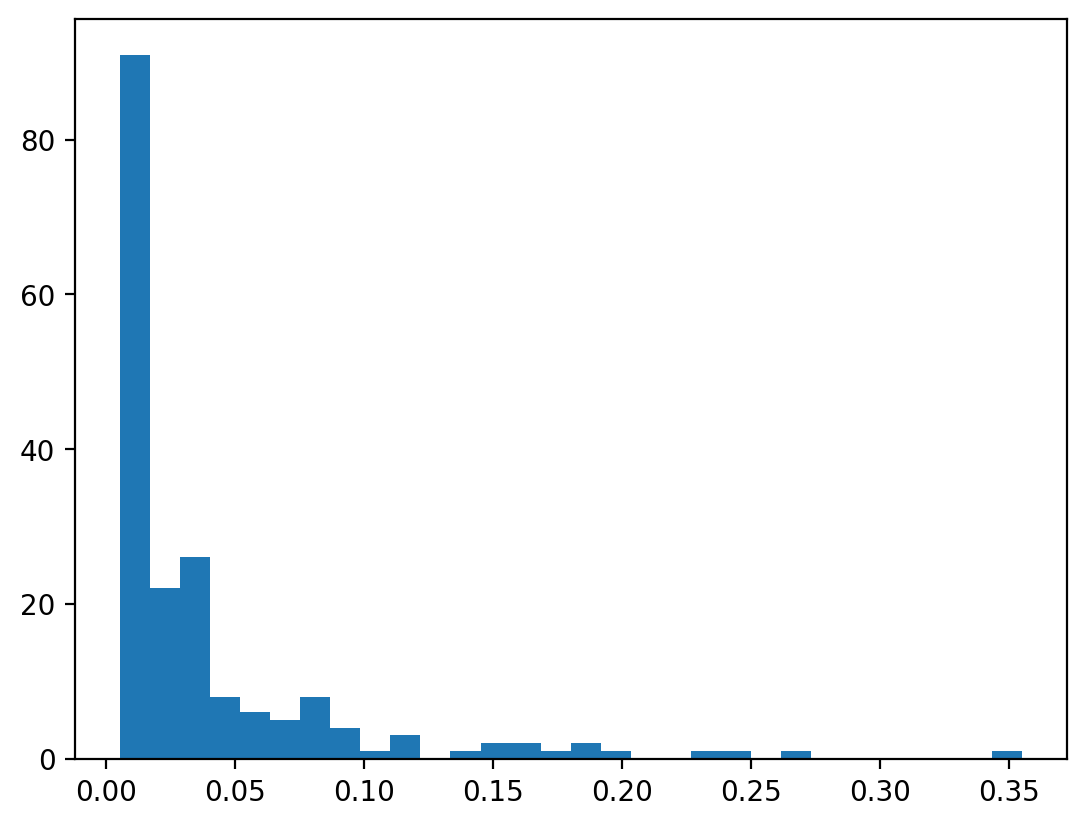
The above plot shows something that is expected, a high portion of characters aren't connected to lot of other characters while some characters are highly connected all through the network. A close real world example of this is a social network like Twitter where a few people have millions of connections(followers) but majority of users aren't connected to that many other users. This exponential decay like property resembles power law in real life networks.
# A log-log plot to show the "signature" of power law in graphs.
from collections import Counter
hist = Counter(deg_cen_book1.values())
plt.scatter(np.log2(list(hist.keys())), np.log2(list(hist.values())), alpha=0.9)
plt.show()
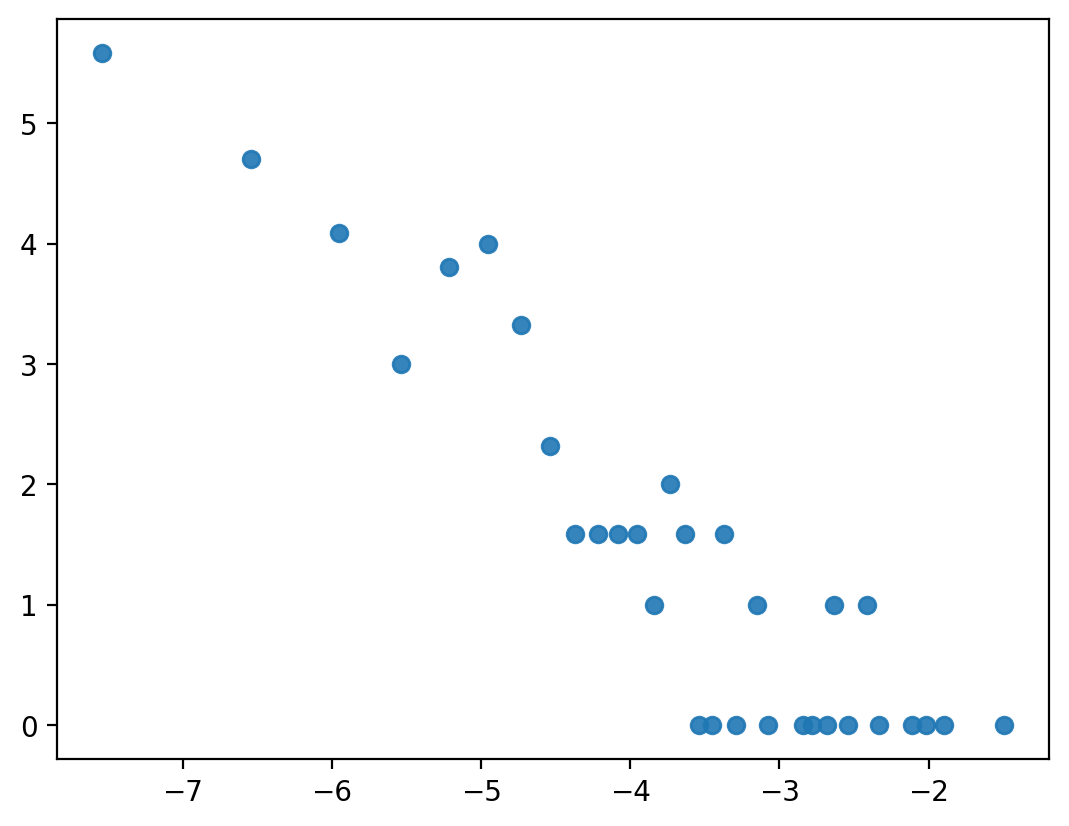
Exercise
Create a new centrality measure, weighted_degree(Graph, weight) which takes in Graph and the weight attribute and returns a weighted degree dictionary. Weighted degree is calculated by summing the weight of the all edges of a node and find the top five characters according to this measure.
from nams.solutions.got import weighted_degree
plt.hist(list(weighted_degree(graphs[0], "weight").values()), bins=30)
plt.show()
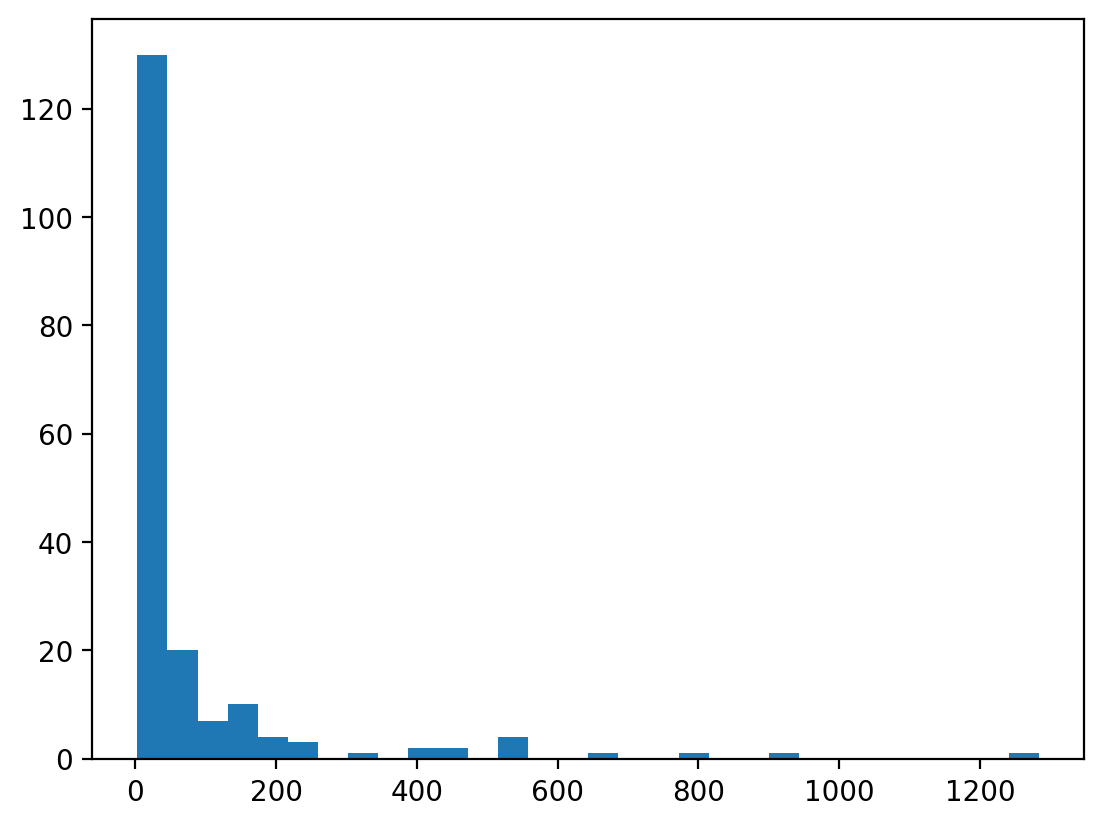
sorted(weighted_degree(graphs[0], "weight").items(), key=lambda x: x[1], reverse=True)[
0:5
]
Betweeness centrality
Let's do this for Betweeness centrality and check if this makes any difference. As different centrality method use different measures underneath, they find nodes which are important in the network. A centrality method like Betweeness centrality finds nodes which are structurally important to the network, which binds the network together and densely.
# First check unweighted (just the structure)
sorted(nx.betweenness_centrality(graphs[0]).items(), key=lambda x: x[1], reverse=True)[
0:10
]
# Let's care about interactions now
sorted(
nx.betweenness_centrality(graphs[0], weight="weight_inv").items(),
key=lambda x: x[1],
reverse=True,
)[0:10]
We can see there are some differences between the unweighted and weighted centrality measures. Another thing to note is that we are using the weight_inv attribute instead of weight(the number of interactions between characters). This decision is based on the way we want to assign the notion of "importance" of a character. The basic idea behind betweenness centrality is to find nodes which are essential to the structure of the network. As betweenness centrality computes shortest paths underneath, in the case of weighted betweenness centrality it will end up penalising characters with high number of interactions. By using weight_inv we will prop up the characters with high interactions with other characters.
PageRank
The billion dollar algorithm, PageRank works by counting the number and quality of links to a page to determine a rough estimate of how important the website is. The underlying assumption is that more important websites are likely to receive more links from other websites.
NOTE: We don't need to worry about weight and weight_inv in PageRank as the algorithm uses weights in the opposite sense (larger weights are better). This may seem confusing as different centrality measures have different definition of weights. So it is always better to have a look at documentation before using weights in a centrality measure.
# by default weight attribute in PageRank is weight
# so we use weight=None to find the unweighted results
sorted(nx.pagerank(graphs[0], weight=None).items(), key=lambda x: x[1], reverse=True)[
0:10
]
sorted(
nx.pagerank(graphs[0], weight="weight").items(), key=lambda x: x[1], reverse=True
)[0:10]
Exercise
Is there a correlation between these techniques?
Find the correlation between these four techniques.
- pagerank (weight = 'weight')
- betweenness_centrality (weight = 'weight_inv')
- weighted_degree
- degree centrality
HINT: Use pandas correlation
from nams.solutions.got import correlation_centrality
correlation_centrality(graphs[0])
Evolution of importance of characters over the books
According to degree centrality the most important character in the first book is Eddard Stark but he is not even in the top 10 of the fifth book. The importance changes over the course of five books, because you know stuff happens ;)
Let's look at the evolution of degree centrality of a couple of characters like Eddard Stark, Jon Snow, Tyrion which showed up in the top 10 of degree centrality in first book.
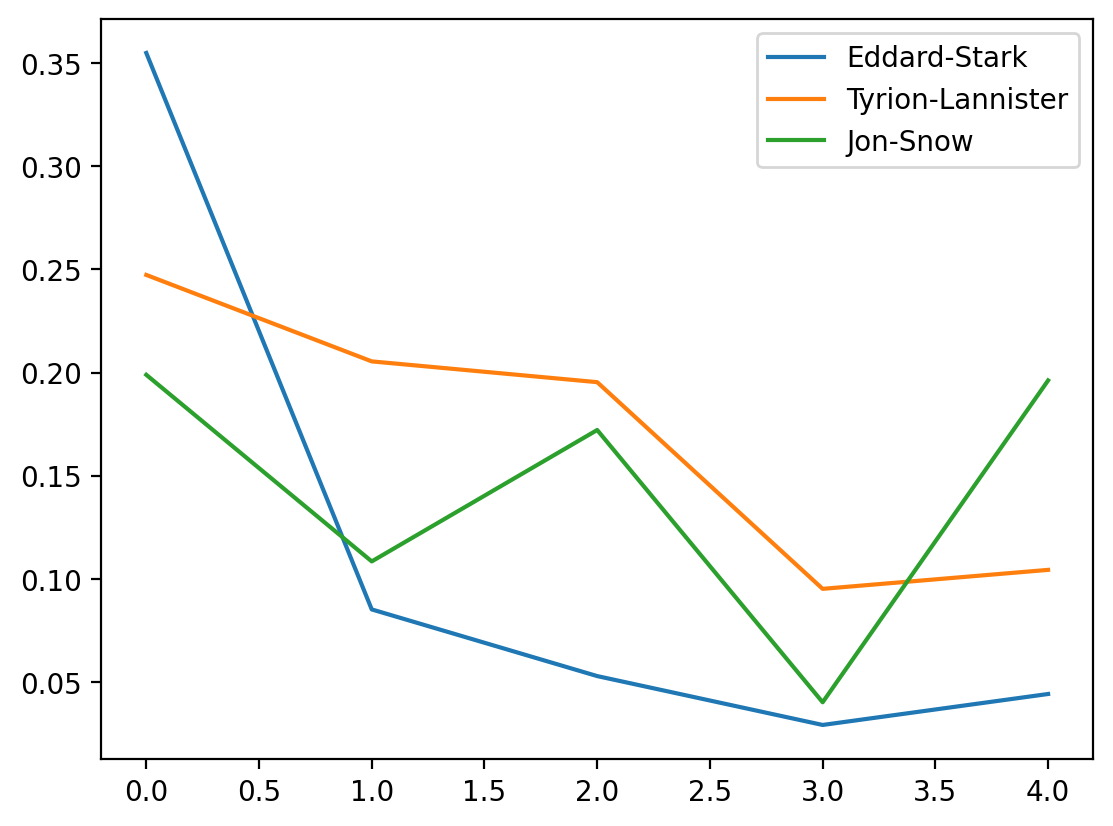
We create a dataframe with character columns and index as books where every entry is the degree centrality of the character in that particular book and plot the evolution of degree centrality Eddard Stark, Jon Snow and Tyrion. We can see that the importance of Eddard Stark in the network dies off and with Jon Snow there is a drop in the fourth book but a sudden rise in the fifth book
evol = [nx.degree_centrality(graph) for graph in graphs]
evol_df = pd.DataFrame.from_records(evol).fillna(0)
evol_df[["Eddard-Stark", "Tyrion-Lannister", "Jon-Snow"]].plot()
plt.show()
set_of_char = set()
for i in range(5):
set_of_char |= set(list(evol_df.T[i].sort_values(ascending=False)[0:5].index))
set_of_char
Exercise
Plot the evolution of betweenness centrality of the above mentioned characters over the 5 books.
from nams.solutions.got import evol_betweenness
evol_betweenness(graphs)
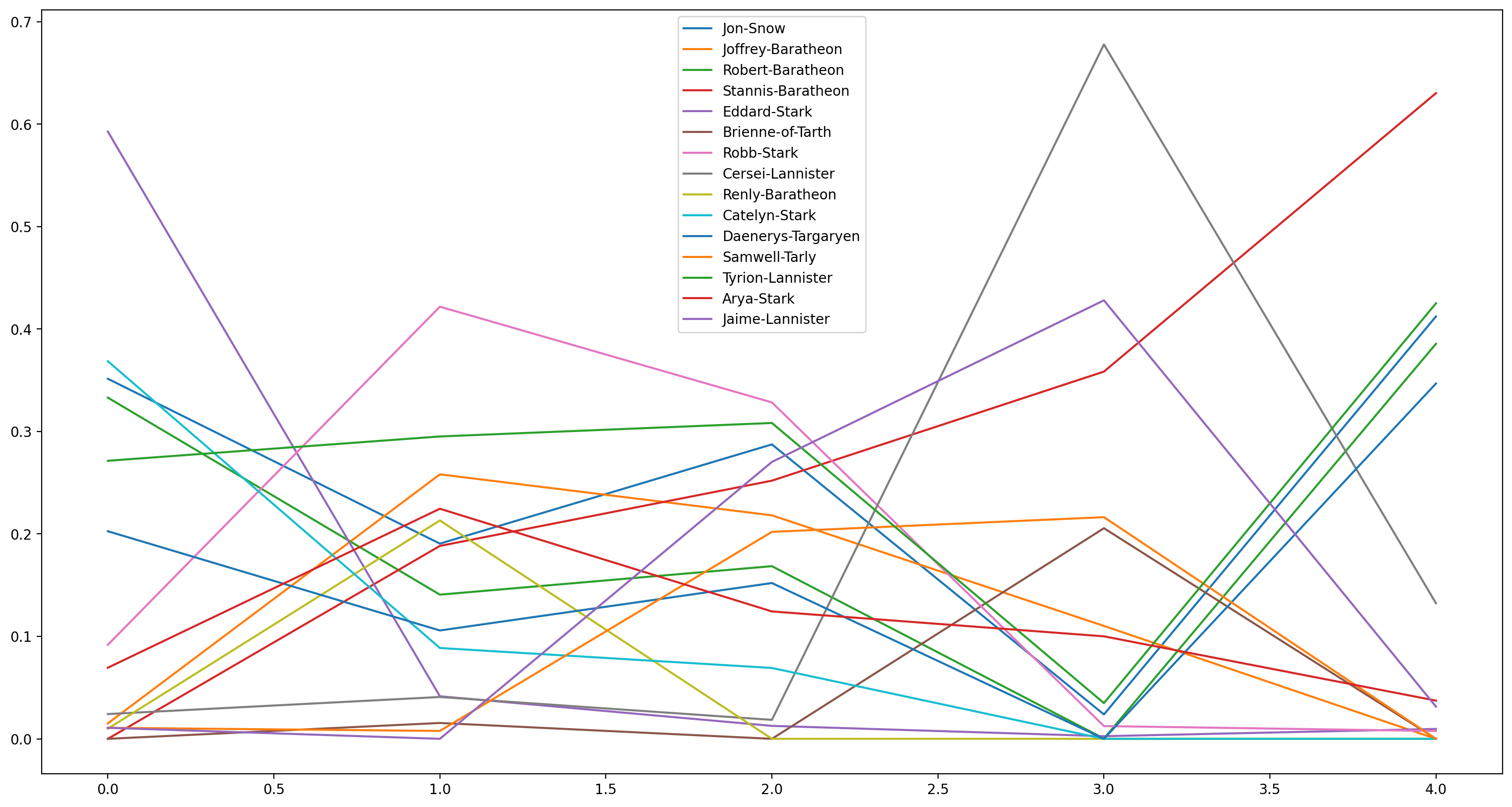
So what's up with Stannis Baratheon?
sorted(nx.degree_centrality(graphs[4]).items(), key=lambda x: x[1], reverse=True)[:5]
sorted(nx.betweenness_centrality(graphs[4]).items(), key=lambda x: x[1], reverse=True)[
:5
]
nx.draw(nx.barbell_graph(5, 1), with_labels=True)
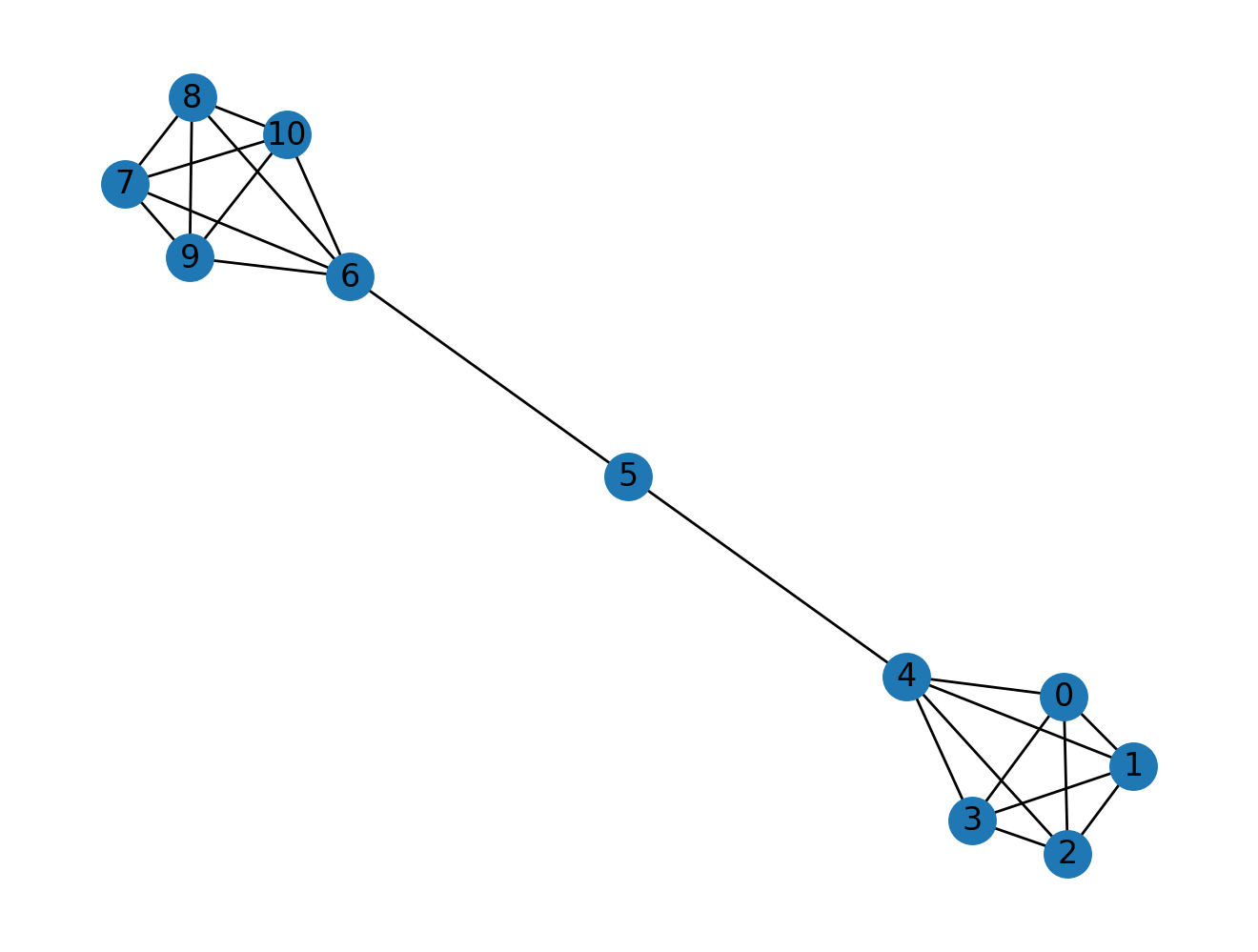
As we know the a higher betweenness centrality means that the node is crucial for the structure of the network, and in the case of Stannis Baratheon in the fifth book it seems like Stannis Baratheon has characterstics similar to that of node 5 in the above example as it seems to be the holding the network together.
As evident from the betweenness centrality scores of the above example of barbell graph, node 5 is the most important node in this network.
nx.betweenness_centrality(nx.barbell_graph(5, 1))
Community detection in Networks
A network is said to have community structure if the nodes of the network can be easily grouped into (potentially overlapping) sets of nodes such that each set of nodes is densely connected internally. There are multiple algorithms and definitions to calculate these communites in a network.
We will use louvain community detection algorithm to find the modules in our graph.
import nxviz as nv
from nxviz import annotate
plt.figure(figsize=(8, 8))
partition = community.best_partition(graphs[0], randomize=False)
# Annotate nodes' partitions
for n in graphs[0].nodes():
graphs[0].nodes[n]["partition"] = partition[n]
graphs[0].nodes[n]["degree"] = graphs[0].degree(n)
nv.matrix(graphs[0], group_by="partition", sort_by="degree", node_color_by="partition")
annotate.matrix_block(graphs[0], group_by="partition", color_by="partition")
annotate.matrix_group(graphs[0], group_by="partition", offset=-8)
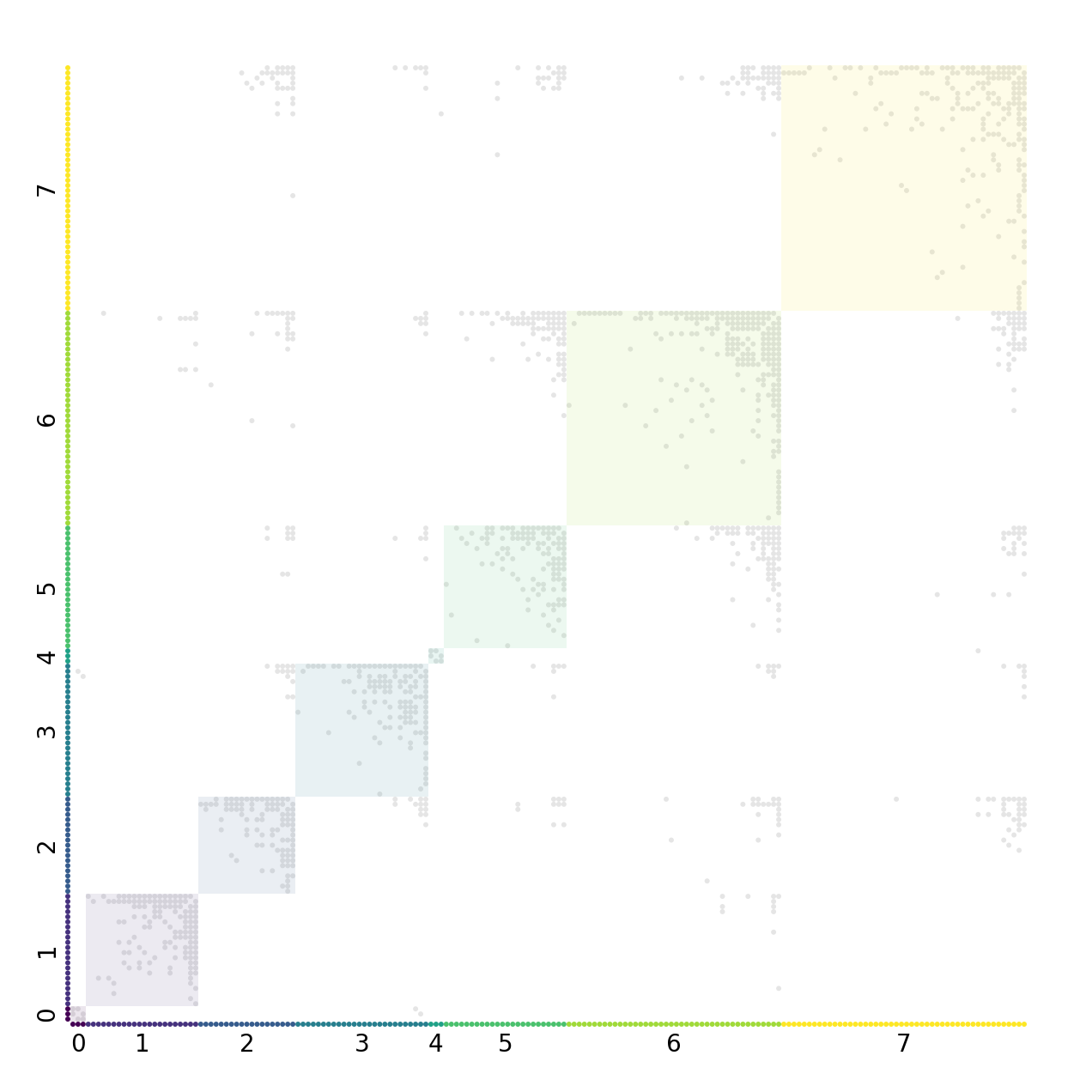
A common defining quality of a community is that the within-community edges are denser than the between-community edges.
# louvain community detection find us 8 different set of communities
partition_dict = {}
for character, par in partition.items():
if par in partition_dict:
partition_dict[par].append(character)
else:
partition_dict[par] = [character]
len(partition_dict)
partition_dict[2]
If we plot these communities of the network we see a denser network as compared to the original network which contains all the characters.
nx.draw(nx.subgraph(graphs[0], partition_dict[3]))
nx.draw(nx.subgraph(graphs[0], partition_dict[1]))
We can test this by calculating the density of the network and the community.
Like in the following example the network between characters in a community is 5 times more dense than the original network.
nx.density(nx.subgraph(graphs[0], partition_dict[4])) / nx.density(graphs[0])
Exercise
Find the most important node in the partitions according to degree centrality of the nodes using the partition_dict we have already created.
from nams.solutions.got import most_important_node_in_partition
most_important_node_in_partition(graphs[0], partition_dict)
Solutions
Here are the solutions to the exercises above.
from nams.solutions import got
import inspect
print(inspect.getsource(got))